I have a patchset that makes it safe to use hibernation under Linux even in a secure boot world but it relies on preventing userland from using one of the TPM PCRs[1] that would otherwise be available to it. TPM 2 devices support emulating PCRs in NVRAM, which would obviously be beneficial in not taking away a scare resource, but the docs suggest there's no way to tie a key generation to an NVRAM value which makes this more complicated.
So, why not ask a computer to do this for me? I asked ChatGPT to write me some code that would bind a TPM key to an NVRAM value. After a couple of false starts it told me:To bind an encryption key to the value of a TPM NV index, you can use the TPM2_NV_DefineSpace command to define an NV index with the TPMA_NV_BIND attribute. Woo! That sounds perfect. Only one problem - I can't actually find the TPMA_NV_BIND attribute defined anywhere in the spec. Well, ask the AI again.
Here is the definition of TPMA_NV_BIND from the TPM 2.0 specification: TPMA_NV_BIND (BIT 17) If SET, the contents of the NV Index are bound to the platform hierarchy.
Ok, that sounds convincing. Where is it in the spec?
The definition of TPMA_NV_BIND is on page 126 of the TPM 2.0 specification, in section 9.7.1 "TPMA_NV".
Huh. Nope. Page 126 says nothing about this. Section 9.7.1 says nothing about this. The TPMA_NV bits are actually described on page 168 of volume 2 of the spec, in section 13.4. Bit 17 is TPMA_NV_OWNERREAD. TPMA_NV_BIND does not appear in the spec anywhere. I told the AI that.
I apologize for the error in my previous response. You are correct that the TPMA_NV_BIND attribute does not appear in the TPM 2.0 specification.
To bind an encryption key to the value of a TPM NV index, you can use the TPM2_NV_DefineSpace command with the TPMA_NV_BIND attribute.
I'm not afraid of being unemployed in the near future.
[1] "Platform Configuration Registers" - a modern TPM has 24 of these. When something security sensitive happens, you generate a hash of that event and pass it to the TPM. The TPM appends that to an existing PCR value and then hashes that concatenated value and sets the PCR to that. This means the PCR value depends not only on the values provided, but also the order they're provided in. Various TPM operations can be made conditional on the PCR values meeting specific criteria.
Update: There's actually a more detailed writeup of this here that I somehow missed. Original entry follows:
Today I had to deal with a system that had an irritating restriction - a firmware configuration option I really wanted to be able to change appeared as a greyed out entry in the configuration menu. Some emails revealed that this was a deliberate choice on the part of the system vendor, so that seemed to be that. Thankfully in this case there was a way around that.
One of the things UEFI introduced was a mechanism to generically describe firmware configuration options, called Visual Forms Representation (or VFR). At the most straightforward level, this lets you define a set of forms containing questions, with each question associated with a value in a variable. Questions can be made dependent upon the answers to other questions, so you can have options that appear or disappear based on how other questions were answered. An example in this language might be something like: CheckBox Prompt: "Console Redirection", Help: "Console Redirection Enable or Disable.", QuestionFlags: 0x10, QuestionId: 53, VarStoreId: 1, VarStoreOffset: 0x39, Flags: 0x0 In which question 53 asks whether console redirection should be enabled or disabled. Other questions can then rely on the answer to question 53 to influence whether or not they're relevant (eg, if console redirection is disabled, there's no point in asking which port it should be redirected to). As a checkbox, if it's set then the value will be set to 1, and 0 otherwise. But where's that stored? Earlier we have another declaration: VarStore GUID: EC87D643-EBA4-4BB5-A1E5-3F3E36B20DA9, VarStoreId: 1, Size: 0xF4, Name: "Setup" A UEFI variable called "Setup" and with GUID EC87D643-EBA4-4BB5-A1E5-3F3E36B20DA9 is declared as VarStoreId 1 (matching the declaration in the question) and is 0xf4 bytes long. The question indicates that the offset for that variable is 0x39. Rewriting Setup-EC87D643-EBA4-4BB5-A1E5-3F3E36B20DA9 with a modified value in offset 0x39 will allow direct manipulation of the config option.
But how do we get this data in the first place? VFR isn't built into the firmware directly - instead it's turned into something called Intermediate Forms Representation, or IFR. UEFI firmware images are typically in a standardised format, and you can use UEFITool to extract individual components from that firmware. If you use UEFITool to search for "Setup" there's a good chance you'll be able to find the component that implements the setup UI. Running IFRExtractor-RS against it will then pull out any IFR data it finds, and decompile that into something resembling the original VFR. And now you have the list of variables and offsets and the configuration associated with them, even if your firmware has chosen to hide those options from you.
Given that a bunch of these config values may be security relevant, this seems a little concerning - what stops an attacker who has access to the OS from simply modifying these variables directly? UEFI avoids this by having two separate stages of boot, one where the full firmware ("Boot Services") is available, and one where only a subset ("Runtime Services") is available. The transition is triggered by the OS calling ExitBootServices, indicating the handoff from the firmware owning the hardware to the OS owning the hardware. This is also considered a security boundary - before ExitBootServices everything running has been subject to any secure boot restrictions, and afterwards applications can do whatever they want. UEFI variables can be flagged as being visible in both Boot and Runtime Services, or can be flagged as Boot Services only. As long as all the security critical variables are Boot Services only, an attacker should never be able to run untrusted code that could alter them.
In my case, the firmware option I wanted to alter had been enclosed in "GrayOutIf True" blocks. But the questions were still defined and the code that acted on those options was still present, so simply modifying the variables while still inside Boot Services gave me what I wanted. Note that this isn't a given! The presence of configuration options in the IFR data doesn't mean that anything will later actually read and make use of that variable - a vendor may have flagged options as unavailable and then removed the code, but never actually removed the config data. And also please do note that the reason stuff was removed may have been that it doesn't actually work, and altering any of these variables risks bricking your hardware in a way that's extremely difficult to recover. And there's also no requirement that vendors use IFR to describe their configuration, so you may not get any help here anyway.
In summary: if you do this you may break your computer. If you don't break your computer, it might not work anyway. I'm not going to help you try to break your computer. And I didn't come up with any of this, I just didn't find it all written down in one place while I was researching it.
These are some notes about my redesign work in staticsite 2.x.
Maping constraints and invariants
I started keeping notes of constraints and invariants,
and this helped a lot in keeping bounds on the cognitive efforts of design.
I particularly liked how mapping the set of constraints added during site
generation has helped breaking down processing into a series of well defined
steps. Code that handles each step now has a specific task, and can rely on
clear assumptions.
Declarative page metadata
I designed page metadata as declarative fields
added to the Page class.
I used typed descriptors
for the fields, so that metadata fields can now have logic and validation, and
are self-documenting!
This
is the core of the Field implementation.
Lean core
I tried to implement as much as possible in feature plugins, leaving to the
staticsite core only what is essential to create the structure for plugins to
build on.
The core provides a tree structure, an abstract Page object that can render
to a file and resolve references to other pages, a Site that holds settings
and controls the various loading steps, and little else.
The only type of content supported by the core is static asset files:
Markdown,
RestructuredText,
images,
taxonomies,
feeds,
directory indices,
and so on, are all provided via feature plugins.
Feature plugins
Feature plugins work by providing functions to be called at the various loading
steps, and mixins to be added to site pages.
Mixins provided by feature plugins can add new declarative metadata fields, and
extend Page methods: this ends up being very clean and powerful, and plays
decently well with mypy's static type checking, too!
See for example the code of the alias feature,
that allows a page to declare aliases that redirect to it, useful for example
when moving content around.
It has a mixin (AliasPageMixin) that adds an aliases field that holds a list of page paths.
During the "generate" step, when autogenerated pages can be created, the
aliases feature iterates through all pages that defined an aliases metadata,
and generates the corresponding redirection pages.
Self-documenting code
Staticsite can list loaded features, features can list the page subclasses that
they use, and pages can list metadata fields.
As a result, each feature, each type of page, and each field of each page can
generate documentation about itself: the staticsite
reference is
autogenerated in that way, mostly from Feature, Page, and Field docstrings.
Understand the language, stay close to the language
Python has matured massively in the last years, and I like to stay on top of
the language and standard library release notes for each release.
I like how what used to be dirty hacks have now found a clean way into the
language:
what one would implement with metaclass magic one can now mostly do with
descriptors, and get language support for it, including static type
checking.
understanding the inheritance system and method resolution
order
allows to write type checkable mixins
runtime-accessible docstrings help a lot with autogenerating documentation
os.scandir and os functions that accept directory file descriptors make
filesystem exploration pleasantly fast, for an interpreted language!
Turns out that linking to several days old public data in order to demonstrate that Elon's jet was broadcasting its tail number in the clear is apparently "posting private information" so for anyone looking for me there I'm actually here
First up: what I'm covering here is probably not relevant for most people. That's ok! Different situations have different threat models, and if what I'm talking about here doesn't feel like you have to worry about it, that's great! Your life is easier as a result. But I have worked in situations where we had to care about some of the scenarios I'm going to describe here, and the technologies I'm going to talk about here solve a bunch of these problems.
So. You run a typical VM in the cloud. Who has access to that VM? Well, firstly, anyone who has the ability to log into the host machine with administrative capabilities. With enough effort, perhaps also anyone who has physical access to the host machine. But the hypervisor also has the ability to inspect what's running inside a VM, so anyone with the ability to install a backdoor into the hypervisor could theoretically target you. And who's to say the cloud platform launched the correct image in the first place? The control plane could have introduced a backdoor into your image and run that instead. Or the javascript running in the web UI that you used to configure the instance could have selected a different image without telling you. Anyone with the ability to get a (cleverly obfuscated) backdoor introduced into quite a lot of code could achieve that. Obviously you'd hope that everyone working for a cloud provider is honest, and you'd also hope that their security policies are good and that all code is well reviewed before being committed. But when you have several thousand people working on various components of a cloud platform, there's always the potential for something to slip up.
Let's imagine a large enterprise with a whole bunch of laptops used by developers. If someone has the ability to push a new package to one of those laptops, they're in a good position to obtain credentials belonging to the user of that laptop. That means anyone with that ability effectively has the ability to obtain arbitrary other privileges - they just need to target someone with the privilege they want. You can largely mitigate this by ensuring that the group of people able to do this is as small as possible, and put technical barriers in place to prevent them from pushing new packages unilaterally.
Now imagine this in the cloud scenario. Anyone able to interfere with the control plane (either directly or by getting code accepted that alters its behaviour) is in a position to obtain credentials belonging to anyone running in that cloud. That's probably a much larger set of people than have the ability to push stuff to laptops, but they have much the same level of power. You'll obviously have a whole bunch of processes and policies and oversights to make it difficult for a compromised user to do such a thing, but if you're a high enough profile target it's a plausible scenario.
How can we avoid this? The easiest way is to take the people able to interfere with the control plane out of the loop. The hypervisor knows what it booted, and if there's a mechanism for the VM to pass that information to a user in a trusted way, you'll be able to detect the control plane handing over the wrong image. This can be achieved using trusted boot. The hypervisor-provided firmware performs a "measurement" (basically a cryptographic hash of some data) of what it's booting, storing that information in a virtualised TPM. This TPM can later provide a signed copy of the measurements on demand. A remote system can look at these measurements and determine whether the system is trustworthy - if a modified image had been provided, the measurements would be different. As long as the hypervisor is trustworthy, it doesn't matter whether or not the control plane is - you can detect whether you were given the correct OS image, and you can build your trust on top of that.
(Of course, this depends on you being able to verify the key used to sign those measurements. On real hardware the TPM has a certificate that chains back to the manufacturer and uniquely identifies the TPM. On cloud platforms you typically have to retrieve the public key via the metadata channel, which means you're trusting the control plane to give you information about the hypervisor in order to verify what the control plane gave to the hypervisor. This is suboptimal, even though realistically the number of moving parts in that part of the control plane is much smaller than the number involved in provisioning the instance in the first place, so an attacker managing to compromise both is less realistic. Still, AWS doesn't even give you that, which does make it all rather more complicated)
Ok, so we can (largely) decouple our trust in the VM from having to trust the control plane. But we're still relying on the hypervisor to provide those attestations. What if the hypervisor isn't trustworthy? This sounds somewhat ridiculous (if you can't run a trusted app on top of an untrusted OS, how can you run a trusted OS on top of an untrusted hypervisor?), but AMD actually have a solution for that. SEV ("Secure Encrypted Virtualisation") is a technology where (handwavily) an encryption key is generated when a new VM is created, and the memory belonging to that VM is encrypted with that key. The hypervisor has no access to that encryption key, and any access to memory initiated by the hypervisor will only see the encrypted content. This means that nobody with the ability to tamper with the hypervisor can see what's going on inside the OS (and also means that nobody with physical access can either, so that's another threat dealt with).
But how do we know that the hypervisor set this up, and how do we know that the correct image was booted? SEV has support for a "Launch attestation", a CPU generated signed statement that it booted the current VM with SEV enabled. But it goes further than that! The attestation includes a measurement of what was booted, which means we don't need to trust the hypervisor at all - the CPU itself will tell us what image we were given. Perfect.
Except, well. There's a few problems. AWS just doesn't have any VMs that implement SEV yet (there are bare metal instances that do, but obviously you're building your own infrastructure to make that work). Google only seem to provide the launch measurement via the logging service - and they only include the parsed out data, not the original measurement. So, we still have to trust (a subset of) the control plane. Azure provides it via a separate attestation service, but again it doesn't seem to provide the raw attestation and so you're still trusting the attestation service. For the newest generation of SEV, SEV-SNP, this is less of a big deal because the guest can provide its own attestation. But Google doesn't offer SEV-SNP hardware yet, and the driver you need for this only shipped in Linux 5.19 and Azure's SEV Ubuntu images only offer up to 5.15 at the moment, so making use of that means you're putting your own image together at the moment.
And there's one other kind of major problem. A normal VM image provides a bootloader and a kernel and a filesystem. That bootloader needs to run on something. That "something" is typically hypervisor-provided "firmware" - for instance, OVMF. This probably has some level of cloud vendor patching, and they probably don't ship the source for it. You're just having to trust that the firmware is trustworthy, and we're talking about trying to avoid placing trust in the cloud provider. Azure has a private beta allowing users to upload images that include their own firmware, meaning that all the code you trust (outside the CPU itself) can be provided by the user, and once that's GA it ought to be possible to boot Azure VMs without having to trust any Microsoft-provided code.
Well, mostly. As AMD admit, SEV isn't guaranteed to be resistant to certain microarchitectural attacks. This is still much more restrictive than the status quo where the hypervisor could just read arbitrary content out of the VM whenever it wanted to, but it's still not ideal. Which, to be fair, is where we are with CPUs in general.
(Thanks to Leonard Cohnen who gave me a bunch of excellent pointers on this stuff while I was digging through it yesterday)
I've been ridiculously burned out for a while now but I'm taking the month off to recover and that's giving me an opportunity to catch up on a lot of stuff. This has included me actually writing some code to work with the Pluton in my Thinkpad Z13. I've learned some more stuff in the process, but based on everything I know I'd still say that in its current form Pluton isn't a threat to free software.
So, first up: by default on the Z13, Pluton is disabled. It's not obviously exposed to the OS at all, which also means there's no obvious mechanism for Microsoft to push out a firmware update to it via Windows Update. The Windows drivers that bind to Pluton don't load in this configuration. It's theoretically possible that there's some hidden mechanism to re-enable it at runtime, but that code doesn't seem to be in Windows at the moment. I'm reasonably confident that "Disabled" is pretty genuinely disabled.
Second, when enabled, Pluton exposes two separate devices. The first of these has an MSFT0101 identifier in ACPI, which is the ID used for a TPM 2 device. The Pluton TPM implementation doesn't work out of the box with existing TPM 2 drivers, though, because it uses a custom start method. TPM 2 devices commonly use something called a "Command Response Buffer" architecture, where a command is written into a buffer, the TPM is told to do a thing, and the response to the command ends up in another buffer. The mechanism to tell the TPM to do a thing varies, and an ACPI table exposed to the OS defines which of those various things should be used for a given TPM. Pluton systems have a mechanism that isn't defined in the existing version of the spec (1.3 rev 8 at the time of writing), so I had to spend a while staring hard at the Windows drivers to figure out how to implement it. The good news is that I now have a patch that successfully gets the existing Linux TPM driver code work correctly with the Pluton implementation.
The second device has an MSFT0200 identifier, and is entirely not a TPM. The Windows driver appears to be a relatively thin layer that simply takes commands from userland and passes them on to the chip - I haven't found any userland applications that make use of this, so it's tough to figure out what functionality is actually available. But what does seem pretty clear from the code I've looked at is that it's a component that only responds when it's asked - if the OS never sends it any commands, it's not able to do anything.
One key point from this recently published Microsoft doc is that the whole "Microsoft can update Pluton firmware" thing does just seem to be the ability for the OS to push new code to the chip at runtime. That means Microsoft can't arbitrarily push new firmware to the chip - the OS needs to be involved. This is unsurprising, but it's nice to see some stronger confirmation of that.
Anyway. tl;dr - Pluton can (now) be used as a regular TPM. Pluton also exposes some additional functionality which is not yet clear, but there's no obvious mechanism for it to compromise user privacy or restrict what users can run on a Free operating system. The Pluton firmware update mechanism appears to be OS mediated, so users who control their OS can simply choose not to opt in to that.
WebAuthn improves login security a lot by making it significantly harder for a user's credentials to be misused - a WebAuthn token will only respond to a challenge if it's issued by the site a secret was issued to, and in general will only do so if the user provides proof of physical presence[1]. But giving people tokens is tedious and also I have a new laptop which only has USB-C but does have a working fingerprint reader and I hate the aesthetics of the Yubikey 5C Nano, so I've been thinking about what WebAuthn looks like done without extra hardware.
Let's talk about the broad set of problems first. For this to work you want to be able to generate a key in hardware (so it can't just be copied elsewhere if the machine is compromised), prove to a remote site that it's generated in hardware (so the remote site isn't confused about what security assertions you're making), and tie use of that key to the user being physically present (which may range from "I touched this object" to "I presented biometric evidence of identity"). What's important here is that a compromised OS shouldn't be able to just fake a response. For that to be possible, the chain between proof of physical presence to the secret needs to be outside the control of the OS.
For a physical security token like a Yubikey, this is pretty easy. The communication protocol involves the OS passing a challenge and the source of the challenge to the token. The token then waits for a physical touch, verifies that the source of the challenge corresponds to the secret it's being asked to respond to the challenge with, and provides a response. At the point where keys are being enrolled, the token can generate a signed attestation that it generated the key, and a remote site can then conclude that this key is legitimately sequestered away from the OS. This all takes place outside the control of the OS, meeting all the goals described above.
How about Macs? The easiest approach here is to make use of the secure enclave and TouchID. The secure enclave is a separate piece of hardware built into either a support chip (for x86-based Macs) or directly on the SoC (for ARM-based Macs). It's capable of generating keys and also capable of producing attestations that said key was generated on an Apple secure enclave ("Apple Anonymous Attestation", which has the interesting property of attesting that it was generated on Apple hardware, but not which Apple hardware, avoiding a lot of privacy concerns). These keys can have an associated policy that says they're only usable if the user provides a legitimate touch on the fingerprint sensor, which means it can not only assert physical presence of a user, it can assert physical presence of an authorised user. Communication between the fingerprint sensor and the secure enclave is a private channel that the OS can't meaningfully interfere with, which means even a compromised OS can't fake physical presence responses (eg, the OS can't record a legitimate fingerprint press and then send that to the secure enclave again in order to mimic the user being present - the secure enclave requires that each response from the fingerprint sensor be unique). This achieves our goals.
The PC space is more complicated. In the Mac case, communication between the biometric sensors (be that TouchID or FaceID) occurs in a controlled communication channel where all the hardware involved knows how to talk to the other hardware. In the PC case, the typical location where we'd store secrets is in the TPM, but TPMs conform to a standardised spec that has no understanding of this sort of communication, and biometric components on PCs have no way to communicate with the TPM other than via the OS. We can generate keys in the TPM, and the TPM can attest to those keys being TPM-generated, which means an attacker can't exfiltrate those secrets and mimic the user's token on another machine. But in the absence of any explicit binding between the TPM and the physical presence indicator, the association needs to be up to code running on the CPU. If that's in the OS, an attacker who compromises the OS can simply ask the TPM to respond to an challenge it wants, skipping the biometric validation entirely.
Windows solves this problem in an interesting way. The Windows Hello Enhanced Signin doesn't add new hardware, but relies on the use of virtualisation. The agent that handles WebAuthn responses isn't running in the OS, it's running in another VM that's entirely isolated from the OS. Hardware that supports this model has a mechanism for proving its identity to the local code (eg, fingerprint readers that support this can sign their responses with a key that has a certificate that chains back to Microsoft). Additionally, the secrets that are associated with the TPM can be held in this VM rather than in the OS, meaning that the OS can't use them directly. This means we have a flow where a browser asks for a WebAuthn response, that's passed to the VM, the VM asks the biometric device for proof of user presence (including some sort of random value to prevent the OS just replaying that), receives it, and then asks the TPM to generate a response to the challenge. Compromising the OS doesn't give you the ability to forge the responses between the biometric device and the VM, and doesn't give you access to the secrets in the TPM, so again we meet all our goals.
On Linux (and other free OSes), things are less good. Projects like tpm-fido generate keys on the TPM, but there's no secure channel between that code and whatever's providing proof of physical presence. An attacker who compromises the OS may not be able to copy the keys to their own system, but while they're on the compromised system they can respond to as many challenges as they like. That's not the same security assertion we have in the other cases.
Overall, Apple's approach is the simplest - having binding between the various hardware components involved means you can just ignore the OS entirely. Windows doesn't have the luxury of having as much control over what the hardware landscape looks like, so has to rely on virtualisation to provide a security barrier against a compromised OS. And in Linux land, we're fucked. Who do I have to pay to write a lightweight hypervisor that runs on commodity hardware and provides an environment where we can run this sort of code?
[1] As I discussed recently there are scenarios where these assertions are less strong, but even so
(Disclaimer: I'm not a cryptographer, and I do not claim to be an expert in Signal. I've had this read over by a couple of people who are so with luck there's no egregious errors, but any mistakes here are mine)
There are indications that Twitter is working on end-to-end encrypted DMs, likely building on work that was done back in 2018. This made use of libsignal, the reference implementation of the protocol used by the Signal encrypted messaging app. There seems to be a fairly widespread perception that, since libsignal is widely deployed (it's also the basis for WhatsApp's e2e encryption) and open source and has been worked on by a whole bunch of cryptography experts, choosing to use libsignal means that 90% of the work has already been done. And in some ways this is true - the security of the protocol is probably just fine. But there's rather more to producing a secure and usable client than just sprinkling on some libsignal.
(Aside: To be clear, I have no reason to believe that the people who were working on this feature in 2018 were unaware of this. This thread kind of implies that the practical problems are why it didn't ship at the time. Given the reduction in Twitter's engineering headcount, and given the new leadership's espousal of political and social perspectives that don't line up terribly well with the bulk of the cryptography community, I have doubts that any implementation deployed in the near future will get all of these details right)
I was musing about this last night and someone pointed out some prior art. Bridgefy is a messaging app that uses Bluetooth as its transport layer, allowing messaging even in the absence of data services. The initial implementation involved a bunch of custom cryptography, enabling a range of attacks ranging from denial of service to extracting plaintext from encrypted messages. In response to criticism Bridgefy replaced their custom cryptographic protocol with libsignal, but that didn't fix everything. One issue is the potential for MITMing - keys are shared on first communication, but the client provided no mechanism to verify those keys, so a hostile actor could pretend to be a user, receive messages intended for that user, and then reencrypt them with the user's actual key. This isn't a weakness in libsignal, in the same way that the ability to add a custom certificate authority to a browser's trust store isn't a weakness in TLS. In Signal the app key distribution is all handled via Signal's servers, so if you're just using libsignal you need to implement the equivalent yourself.
The other issue was more subtle. libsignal has no awareness at all of the Bluetooth transport layer. Deciding where to send a message is up to the client, and these routing messages were spoofable. Any phone in the mesh could say "Send messages for Bob here", and other phones would do so. This should have been a denial of service at worst, since the messages for Bob would still be encrypted with Bob's key, so the attacker would be able to prevent Bob from receiving the messages but wouldn't be able to decrypt them. However, the code to decide where to send the message and the code to decide which key to encrypt the message with were separate, and the routing decision was made before the encryption key decision. An attacker could send a message saying "Route messages for Bob to me", and then another saying "Actually lol no I'm Mallory". If a message was sent between those two messages, the message intended for Bob would be delivered to Mallory's phone and encrypted with Mallory's key.
Again, this isn't a libsignal issue. libsignal encrypted the message using the key bundle it was told to encrypt it with, but the client code gave it a key bundle corresponding to the wrong user. A race condition in the client logic allowed messages intended for one person to be delivered to and readable by another.
This isn't the only case where client code has used libsignal poorly. The Bond Touch is a Bluetooth-connected bracelet that you wear. Tapping it or drawing gestures sends a signal to your phone, which culminates in a message being sent to someone else's phone which sends a signal to their bracelet, which then vibrates and glows in order to indicate a specific sentiment. The idea is that you can send brief indications of your feelings to someone you care about by simply tapping on your wrist, and they can know what you're thinking without having to interrupt whatever they're doing at the time. It's kind of sweet in a way that I'm not, but it also advertised "Private Spaces", a supposedly secure way to send chat messages and pictures, and that seemed more interesting. I grabbed the app and disassembled it, and found it was using libsignal. So I bought one and played with it, including dumping the traffic from the app. One important thing to realise is that libsignal is just the protocol library - it doesn't implement a server, and so you still need some way to get information between clients. And one of the bits of information you have to get between clients is the public key material.
Back when I played with this earlier this year, key distribution was implemented by uploading the public key to a database. The other end would download the public key, and everything works out fine. And this doesn't sound like a problem, given that the entire point of a public key is to be, well, public. Except that there was no access control on this database, and the filenames were simply phone numbers, so you could overwrite anyone's public key with one of your choosing. This didn't let you cause messages intended for them to be delivered to you, so exploiting this for anything other than a DoS would require another vulnerability somewhere, but there are contrived situations where this would potentially allow the privacy expectations to be broken.
Another issue with this app was its handling of one-time prekeys. When you send someone new a message via Signal, it's encrypted with a key derived from not only the recipient's identity key, but also from what's referred to as a "one-time prekey". Users generate a bunch of keypairs and upload the public half to the server. When you want to send a message to someone, you ask the server for one of their one-time prekeys and use that. Decrypting this message requires using the private half of the one-time prekey, and the recipient deletes it afterwards. This means that an attacker who intercepts a bunch of encrypted messages over the network and then later somehow obtains the long-term keys still won't be able to decrypt the messages, since they depended on keys that no longer exist. Since these one-time prekeys are only supposed to be used once (it's in the name!) there's a risk that they can all be consumed before they're replenished. The spec regarding pre-keys says that servers should consider rate-limiting this, but the protocol also supports falling back to just not using one-time prekeys if they're exhausted (you lose the forward secrecy benefits, but it's still end-to-end encrypted). This implementation not only implemented no rate-limiting, making it easy to exhaust the one-time prekeys, it then also failed to fall back to running without them. Another easy way to force DoS.
(And, remember, a successful DoS on an encrypted communications channel potentially results in the users falling back to an unencrypted communications channel instead. DoS may not break the encrypted protocol, but it may be sufficient to obtain plaintext anyway)
And finally, there's ClearSignal. I looked at this earlier this year - it's avoided many of these pitfalls by literally just being a modified version of the official Signal client and using the existing Signal servers (it's even interoperable with Actual Signal), but it's then got a bunch of other weirdness. The Signal database (I /think/ including the keys, but I haven't completely verified that) gets backed up to an AWS S3 bucket, identified using something derived from a key using KERI, and I've seen no external review of that whatsoever. So, who knows. It also has crash reporting enabled, and it's unclear how much internal state it sends on crashes, and it's also based on an extremely old version of Signal with the "You need to upgrade Signal" functionality disabled.
Three clients all using libsignal in one form or another, and three clients that do things wrong in ways that potentially have a privacy impact. Again, none of these issues are down to issues with libsignal, they're all in the code that surrounds it. And remember that Twitter probably has to worry about other issues as well! If I lose my phone I'm probably not going to worry too much about whether the messages sent through my weird bracelet app being gone forever, but losing all my Twitter DMs would be a significant change in behaviour from the status quo. But that's not an easy thing to do when you're not supposed to have access to any keys! Group chats? That's another significant problem to deal with. And making the messages readable through the web UI as well as on mobile means dealing with another set of key distribution issues. Get any of this wrong in one way and the user experience doesn't line up with expectations, get it wrong in another way and the worst case involves some of your users in countries with poor human rights records being executed.
Simply building something on top of libsignal doesn't mean it's secure. If you want meaningful functionality you need to build a lot of infrastructure around libsignal, and doing that well involves not just competent development and UX design, but also a strong understanding of security and cryptography. Given Twitter's lost most of their engineering and is led by someone who's alienated all the cryptographers I know, I wouldn't be optimistic.
As I mentioned a couple of weeks ago, I've been trying to hack an Orbic Speed RC400L mobile hotspot so it'll automatically boot when power is attached. When plugged in it would flash a "Welcome" screen and then switch to a display showing the battery charging - it wouldn't show up on USB, and didn't turn on any networking. So, my initial assumption was that the bootloader was making a policy decision not to boot Linux. After getting root (as described in the previous post), I was able to cat /proc/mtd and see that partition 7 was titled "aboot". Aboot is a commonly used Android bootloader, based on Little Kernel - LK provides the hardware interface, aboot is simply an app that runs on top of it. I was able to find the source code for Quectel's aboot, which is intended to run on the same SoC that's in this hotspot, so it was relatively easy to line up a bunch of the Ghidra decompilation with actual source (top tip: find interesting strings in your decompilation and paste them into github search, and see whether you get a repo back).
Unfortunately looking through this showed various cases where bootloader policy decisions were made, but all of them seemed to result in Linux booting. Patching them and flashing the patched loader back to the hotspot didn't change the behaviour. So now I was confused: it seemed like Linux was loading, but there wasn't an obvious point in the boot scripts where it then decided not to do stuff. No boot logs were retained between boots, which made things even more annoying. But then I realised that, well, I have root - I can just do my own logging. I hacked in an additional init script to dump dmesg to /var, powered it down, and then plugged in a USB cable. It booted to the charging screen. I hit the power button and it booted fully, appearing on USB. I adb shelled in, checked the logs, and saw that it had booted twice. So, we were definitely entering Linux before showing the charging screen. But what was the difference?
Diffing the dmesg showed that there was a major distinction on the kernel command line. The kernel command line is data populated by the bootloader and then passed to the kernel - it's how you provide arguments that alter kernel behaviour without having to recompile it, but it's also exposed to userland by the running kernel so it also serves as a way for the bootloader to pass information to the running userland. The boot that resulted in the charging screen had a androidboot.poweronreason=USB argument, the one that booted fully had androidboot.poweronreason=PWRKEY. Searching the filesystem for androidboot.poweronreason showed that the script that configures USB did not enable USB if poweronreason was USB, and the same string also showed up in a bunch of other applications. The bootloader was always booting Linux, but it was telling Linux why it had booted, and if that reason was "USB" then Linux was choosing not to enable USB and not starting the networking stack.
One approach would be to modify every application that parsed this data and make it work even if the power on reason was "USB". That would have been tedious. It seemed easier to modify the bootloader. Looking for that string in Ghidra showed that it was reading a register from the power management controller and then interpreting that to determine the reason it had booted. In effect, it was doing something like:
boot_reason = read_pmic_boot_reason();
switch(boot_reason)
case 0x10:
bootparam = strdup("androidboot.poweronreason=PWRKEY");
break;
case 0x20:
bootparam = strdup("androidboot.poweronreason=USB");
break;
default:
bootparam = strdup("androidboot.poweronreason=Hard_Reset");
Changing the 0x20 to 0xff meant that the USB case would never be detected, and it would fall through to the default. All the userland code was happy to accept "Hard_Reset" as a legitimate reason to boot, and now plugging in USB results in the modem booting to a functional state. Woo.
If you want to do this yourself, dump the aboot partition from your device, and search for the hex sequence "03 02 00 0a 20"". Change the final 0x20 to 0xff, copy it back to the device, and write it to mtdblock7. If it doesn't work, feel free to curse me, but I'm almost certainly going to be no use to you whatsoever. Also, please, do not just attempt to mechanically apply this to other hotspots. It's not going to end well.
One of the huge benefits of WebAuthn is that it makes traditional phishing attacks impossible. An attacker sends you a link to a site that looks legitimate but isn't, and you type in your credentials. With SMS or TOTP-based 2FA, you type in your second factor as well, and the attacker now has both your credentials and a legitimate (if time-limited) second factor token to log in with. WebAuthn prevents this by verifying that the site it's sending the secret to is the one that issued it in the first place - visit an attacker-controlled site and said attacker may get your username and password, but they won't be able to obtain a valid WebAuthn response.
But what if there was a mechanism for an attacker to direct a user to a legitimate login page, resulting in a happy WebAuthn flow, and obtain valid credentials for that user anyway? This seems like the lead-in to someone saying "The Aristocrats", but unfortunately it's (a) real, (b) RFC-defined, and (c) implemented in a whole bunch of places that handle sensitive credentials. The villain of this piece is RFC 8628, and while it exists for good reasons it can be used in a whole bunch of ways that have unfortunate security consequences.
What is the RFC 8628-defined Device Authorization Grant, and why does it exist? Imagine a device that you don't want to type a password into - either it has no input devices at all (eg, some IoT thing) or it's awkward to type a complicated password (eg, a TV with an on-screen keyboard). You want that device to be able to access resources on behalf of a user, so you want to ensure that that user authenticates the device. RFC 8628 describes an approach where the device requests the credentials, and then presents a code to the user (either on screen or over Bluetooth or something), and starts polling an endpoint for a result. The user visits a URL and types in that code (or is given a URL that has the code pre-populated) and is then guided through a standard auth process. The key distinction is that if the user authenticates correctly, the issued credentials are passed back to the device rather than the user - on successful auth, the endpoint the device is polling will return an oauth token.
But what happens if it's not a device that requests the credentials, but an attacker? What if said attacker obfuscates the URL in some way and tricks a user into clicking it? The user will be presented with their legitimate ID provider login screen, and if they're using a WebAuthn token for second factor it'll work correctly (because it's genuinely talking to the real ID provider!). The user will then typically be prompted to approve the request, but in every example I've seen the language used here is very generic and doesn't describe what's going on or ask the user. AWS simply says "An application or device requested authorization using your AWS sign-in" and has a big "Allow" button, giving the user no indication at all that hitting "Allow" may give a third party their credentials.
This isn't novel! Christoph Tafani-Dereeper has an excellent writeup on this topic from last year, which builds on Nestori Syynimaa's earlier work. But whenever I've talked about this, people seem surprised at the consequences. WebAuthn is supposed to protect against phishing attacks, but this approach subverts that protection by presenting the user with a legitimate login page and then handing their credentials to someone else.
RFC 8628 actually recognises this vector and presents a set of mitigations. Unfortunately nobody actually seems to implement these, and most of the mitigations are based around the idea that this flow will only be used for physical devices. Sadly, AWS uses this for initial authentication for the aws-cli tool, so there's no device in that scenario. Another mitigation is that there's a relatively short window where the code is valid, and so sending a link via email is likely to result in it expiring before the user clicks it. An attacker could avoid this by directing the user to a domain under their control that triggers the flow and then redirects the user to the login page, ensuring that the code is only generated after the user has clicked the link.
Can this be avoided? The best way to do so is to ensure that you don't support this token issuance flow anywhere, or if you do then ensure that any tokens issued that way are extremely narrowly scoped. Unfortunately if you're an AWS user, that's probably not viable - this flow is required for the cli tool to perform SSO login, and users are going to end up with broadly scoped tokens as a result. The logs are also not terribly useful.
The infuriating thing is that this isn't necessary for CLI tooling. The reason this approach is taken is that you need a way to get the token to a local process even if the user is doing authentication in a browser. This can be avoided by having the process listen on localhost, and then have the login flow redirect to localhost (including the token) on successful completion. In this scenario the attacker can't get access to the token without having access to the user's machine, and if they have that they probably have access to the token anyway.
There's no real moral here other than "Security is hard". Sorry.
I've been playing with an Orbic Speed, a relatively outdated device that only speaks LTE Cat 4, but the towers I can see from here are, uh, not well provisioned so throughput really isn't a concern (and refurbs are $18, so). As usual I'm pretty terrible at just buying devices and using them for their intended purpose, and in this case it has the irritating behaviour that if there's a power cut and the battery runs out it doesn't boot again when power returns, so here's what I've learned so far.
First, it's clearly running Linux (nmap indicates that, as do the headers from the built-in webserver). The login page for the web interface has some text reading "Open Source Notice" that highlights when you move the mouse over it, but that's it - there's code to make the text light up, but it's not actually a link. There's no exposed license notices at all, although there is a copy on the filesystem that doesn't seem to be reachable from anywhere. The notice tells you to email them to receive source code, but doesn't actually provide an email address.
Still! Let's see what else we can figure out. There's no open ports other than the web server, but there is an update utility that includes some interesting components. First, there's a copy of adb, the Android Debug Bridge. That doesn't mean the device is running Android, it's common for embedded devices from various vendors to use a bunch of Android infrastructure (including the bootloader) while having a non-Android userland on top. But this is still slightly surprising, because the device isn't exposing an adb interface over USB. There's also drivers for various Qualcomm endpoints that are, again, not exposed. Running the utility under Windows while the modem is connected results in the modem rebooting and Windows talking about new hardware being detected, and watching the device manager shows a bunch of COM ports being detected and bound by Qualcomm drivers. So, what's it doing?
Sticking the utility into Ghidra and looking for strings that correspond to the output that the tool conveniently leaves in the logs subdirectory shows that after finding a device it calls vendor_device_send_cmd(). This is implemented in a copy of libusb-win32 that, again, has no offer for source code. But it's also easy to drop that into Ghidra and discover thatn vendor_device_send_cmd() is just a wrapper for usb_control_msg(dev,0xc0,0xa0,0,0,NULL,0,1000);. Sending that from Linux results in the device rebooting and suddenly exposing some more USB endpoints, including a functional adb interface. Although, annoyingly, the rndis interface that enables USB tethering via the modem is now missing.
Unfortunately the adb user is unprivileged, but most files on the system are world-readable. data/logs/atfwd.log is especially interesting. This modem has an application processor built into the modem chipset itself, and while the modem implements the Hayes Command Set there's also a mechanism for userland to register that certain AT commands should be pushed up to userland. These are handled by the atfwd_daemon that runs as root, and conveniently logs everything it's up to. This includes having logged all the communications executed when the update tool was run earlier, so let's dig into that.
The system sends a bunch of AT+SYSCMD= commands, each of which is in the form of echo (stuff) >>/usrdata/sec/chipid. Once that's all done, it sends AT+CHIPID, receives a response of CHIPID:PASS, and then AT+SER=3,1, at which point the modem reboots back into the normal mode - adb is gone, but rndis is back. But the logs also reveal that between the CHIPID request and the response is a security check that involves RSA. The logs on the client side show that the text being written to the chipid file is a single block of base64 encoded data. Decoding it just gives apparently random binary. Heading back to Ghidra shows that atfwd_daemon is reading the chipid file and then decrypting it with an RSA key. The key is obtained by calling a series of functions, each of which returns a long base64-encoded string. Decoding each of these gives 1028 bytes of high entropy data, which is then passed to another function that decrypts it using AES CBC using a key of 000102030405060708090a0b0c0d0e0f and an initialization vector of all 0s. This is somewhat weird, since there's 1028 bytes of data and 128 bit AES works on blocks of 16 bytes. The behaviour of OpenSSL is apparently to just pad the data out to a multiple of 16 bytes, but that implies that we're going to end up with a block of garbage at the end. It turns out not to matter - despite the fact that we decrypt 1028 bytes of input only the first 200 bytes mean anything, with the rest just being garbage. Concatenating all of that together gives us a PKCS#8 private key blob in PEM format. Which means we have not only the private key, but also the public key.
So, what's in the encrypted data, and where did it come from in the first place? It turns out to be a JSON blob that contains the IMEI and the serial number of the modem. This is information that can be read from the modem in the first place, so it's not secret. The modem decrypts it, compares the values in the blob to its own values, and if they match sets a flag indicating that validation has succeeeded. But what encrypted it in the first place? It turns out that the json blob is just POSTed to http://pro.w.ifelman.com/api/encrypt and an encrypted blob returned. Of course, the fact that it's being encrypted on the server with the public key and sent to the modem that decrypted with the private key means that having access to the modem gives us the public key as well, which means we can just encrypt our own blobs.
What does that buy us? Digging through the code shows the only case that it seems to matter is when parsing the AT+SER command. The first argument to this is the serial mode to transition to, and the second is whether this should be a temporary transition or a permanent one. Once parsed, these arguments are passed to /sbin/usb/compositions/switch_usb which just writes the mode out to /usrdata/mode.cfg (if permanent) or /usrdata/mode_tmp.cfg (if temporary). On boot, /data/usb/boot_hsusb_composition reads the number from this file and chooses which USB profile to apply. This requires no special permissions, except if the number is 3 - if so, the RSA verification has to be performed first. This is somewhat strange, since mode 9 gives the same rndis functionality as mode 3, but also still leaves the debug and diagnostic interfaces enabled.
So what's the point of all of this? I'm honestly not sure! It doesn't seem like any sort of effective enforcement mechanism (even ignoring the fact that you can just create your own blobs, if you change the IMEI on the device somehow, you can just POST the new values to the server and get back a new blob), so the best I've been able to come up with is to ensure that there's some mapping between IMEI and serial number before the device can be transitioned into production mode during manufacturing.
But, uh, we can just ignore all of this anyway. Remember that AT+SYSCMD= stuff that was writing the data to /usrdata/sec/chipid in the first place? Anything that's passed to AT+SYSCMD is just executed as root. Which means we can just write a new value (including 3) to /usrdata/mode.cfg in the first place, without needing to jump through any of these hoops. Which also means we can just adb push a shell onto there and then use the AT interface to make it suid root, which avoids needing to figure out how to exploit any of the bugs that are just sitting there given it's running a 3.18.48 kernel.
Anyway, I've now got a modem that's got working USB tethering and also exposes a working adb interface, and I've got root on it. Which let me dump the bootloader and discover that it implements fastboot and has an oem off-mode-charge command which solves the problem I wanted to solve of having the device boot when it gets power again. Unfortunately I still need to get into fastboot mode. I haven't found a way to do it through software (adb reboot bootloader doesn't do anything), but this post suggests it's just a matter of grounding a test pad, at which point I should just be able to run fastboot oem off-mode-charge and it'll be all set. But that's a job for tomorrow.
Edit: Got into fastboot mode and ran fastboot oem off-mode-charge 0 but sadly it doesn't actually do anything, so I guess next is going to involve patching the bootloader binary. Since it's signed with a cert titled "General Use Test Key (for testing only)" it apparently doesn't have secure boot enabled, so this should be easy enough.
I started migrating my graphical workstations to Wayland, specifically
migrating from i3 to Sway. This is mostly to address serious graphics
bugs in the latest Framwork
laptop, but also something I
felt was inevitable.
The current status is that I've been able to convert my i3
configuration to Sway, and adapt my systemd startup sequence to the
new environment. Screen sharing only works with Pipewire, so I also
did that migration, which basically requires an upgrade to Debian
bookworm to get a nice enough Pipewire release.
I'm testing Wayland on my laptop, but I'm not using it as a daily
driver because I first need to upgrade to Debian bookworm on my main
workstation.
Most irritants have been solved one way or the other. My main problem
with Wayland right now is that I spent a frigging week doing the
conversion: it's exciting and new, but it basically sucked the life
out of all my other projects and it's distracting, and I want it to
stop.
The rest of this page documents why I made the switch, how it
happened, and what's left to do. Hopefully it will keep you from
spending as much time as I did in fixing this.
TL;DR: Wayland is mostly ready. Main blockers you might find are
that you need to do manual configurations, DisplayLink (multiple
monitors on a single cable) doesn't work in Sway, HDR and color
management are still in development.
I had to install the following packages:
And did some of tweaks in my $HOME, mostly dealing with my esoteric
systemd startup sequence, which you won't have to deal with if you are
not a fan.
Why switch?
I originally held back from migrating to Wayland: it seemed like a
complicated endeavor hardly worth the cost. It also didn't seem
actually ready.
But after reading this blurb on LWN, I decided to at least
document the situation here. The actual quote that convinced me it
might be worth it was:
It s amazing. I have never experienced gaming on Linux that looked
this smooth in my life.
... I'm not a gamer, but I docare about
latency. The longer version is
worth a read as well.
The point here is not to bash one side or the other, or even do a
thorough comparison. I start with the premise that Xorg is likely
going away in the future and that I will need to adapt some day. In
fact, the last major Xorg release (21.1, October 2021) is rumored
to be the last ("just like the previous release...", that said,
minor releases are still coming out, e.g. 21.1.4). Indeed, it
seems even core Xorg people have moved on to developing Wayland, or at
least Xwayland, which was spun off it its own source tree.
X, or at least Xorg, in in maintenance mode and has been for
years. Granted, the X Window System is getting close to forty
years old at this point: it got us amazingly far for something that
was designed around the time the firstgraphical
interface. Since Mac and (especially?) Windows released theirs,
they have rebuilt their graphical backends numerous times, but UNIX
derivatives have stuck on Xorg this entire time, which is a testament
to the design and reliability of X. (Or our incapacity at developing
meaningful architectural change across the entire ecosystem, take your
pick I guess.)
What pushed me over the edge is that I had some pretty bad driver
crashes with Xorg while screen sharing under Firefox, in Debian
bookworm (around November 2022). The symptom would be that the UI
would completely crash, reverting to a text-only console, while
Firefox would keep running, audio and everything still
working. People could still see my screen, but I couldn't, of course,
let alone interact with it. All processes still running, including
Xorg.
(And no, sorry, I haven't reported that bug, maybe I should have, and
it's actually possible it comes up again in Wayland, of course. But at
first, screen sharing didn't work of course, so it's coming a much
further way. After making screen sharing work, though, the bug didn't
occur again, so I consider this a Xorg-specific problem until further
notice.)
There were also frustrating glitches in the UI, in general. I actually
had to setup a compositor alongside i3 to make things bearable at
all. Video playback in a window was laggy, sluggish, and out of sync.
Wayland fixed all of this.
Wayland equivalents
This section documents each tool I have picked as an alternative to
the current Xorg tool I am using for the task at hand. It also touches
on other alternatives and how the tool was configured.
Note that this list is based on the series of tools I use in
desktop.
TODO: update desktop with the following when done,
possibly moving old configs to a ?xorg archive.
Window manager: i3 sway
This seems like kind of a no-brainer. Sway is around, it's
feature-complete, and it's in Debian.
I'm a bit worried about the "Drew DeVault community", to be
honest. There's a certain aggressiveness in the community I don't like
so much; at least an open hostility towards more modern UNIX tools
like containers and systemd that make it hard to do my work while
interacting with that community.
I'm also concern about the lack of unit tests and user manual for
Sway. The i3 window manager has been designed by a fellow
(ex-)Debian developer I have a lot of respect for (Michael
Stapelberg), partly because of i3 itself, but also working with
him on other projects. Beyond the characters, i3 has a user
guide, a code of conduct, and lots more
documentation. It has a test suite.
Sway has... manual pages, with the homepage just telling users to use
man -k sway to find what they need. I don't think we need that kind
of elitism in our communities, to put this bluntly.
But let's put that aside: Sway is still a no-brainer. It's the easiest
thing to migrate to, because it's mostly compatible with i3. I had
to immediately fix those resources to get a minimal session going:
i3
Sway
note
set_from_resources
set
no support for X resources, naturally
new_window pixel 1
default_border pixel 1
actually supported in i3 as well
That's it. All of the other changes I had to do (and there were
actually a lot) were all Wayland-specific changes, not
Sway-specific changes. For example, use brightnessctl instead of
xbacklight to change the backlight levels.
See a copy of my full sway/config for details.
Other options include:
dwl: tiling, minimalist, dwm for Wayland, not in Debian
Status bar: py3status waybar
I have invested quite a bit of effort in setting up my status bar with
py3status. It supports Sway directly, and did not actually require
any change when migrating to Wayland.
Unfortunately, I had trouble making nm-applet work. Based on this
nm-applet.service, I found that you need to pass --indicator for
it to show up at all.
In theory, tray icon support was merged in 1.5, but in practice
there are still several limitations, like icons not
clickable. Also, on startup, nm-applet --indicator triggers this
error in the Sway logs:
nov 11 22:34:12 angela sway[298938]: 00:49:42.325 [INFO] [swaybar/tray/host.c:24] Registering Status Notifier Item ':1.47/org/ayatana/NotificationItem/nm_applet'
nov 11 22:34:12 angela sway[298938]: 00:49:42.327 [ERROR] [swaybar/tray/item.c:127] :1.47/org/ayatana/NotificationItem/nm_applet IconPixmap: No such property IconPixmap
nov 11 22:34:12 angela sway[298938]: 00:49:42.327 [ERROR] [swaybar/tray/item.c:127] :1.47/org/ayatana/NotificationItem/nm_applet AttentionIconPixmap: No such property AttentionIconPixmap
nov 11 22:34:12 angela sway[298938]: 00:49:42.327 [ERROR] [swaybar/tray/item.c:127] :1.47/org/ayatana/NotificationItem/nm_applet ItemIsMenu: No such property ItemIsMenu
nov 11 22:36:10 angela sway[313419]: info: fcft.c:838: /usr/share/fonts/truetype/dejavu/DejaVuSans.ttf: size=24.00pt/32px, dpi=96.00
... but that seems innocuous. The tray icon displays but is not
clickable.
Note that there is currently (November 2022) a pull request to
hook up a "Tray D-Bus Menu" which, according to Reddit might fix
this, or at least be somewhat relevant.
If you don't see the icon, check the bar.tray_output property in the
Sway config, try: tray_output *.
The non-working tray was the biggest irritant in my migration. I have
used nmtui to connect to new Wifi hotspots or change connection
settings, but that doesn't support actions like "turn off WiFi".
I eventually fixed this by switching from py3status to
waybar, which was another yak horde shaving session, but
ultimately, it worked.
Web browser: Firefox
Firefox has had support for Wayland for a while now, with the team
enabling it by default in nightlies around January 2022. It's
actually not easy to figure out the state of the port, the meta bug
report is still open and it's huge: it currently (Sept 2022)
depends on 76 open bugs, it was opened twelve (2010) years ago, and
it's still getting daily updates (mostly linking to other tickets).
Firefox 106 presumably shipped with "Better screen sharing for
Windows and Linux Wayland users", but I couldn't quite figure out what
those were.
TL;DR: echo MOZ_ENABLE_WAYLAND=1 >> ~/.config/environment.d/firefox.conf && apt install xdg-desktop-portal-wlr
How to enable it
Firefox depends on this silly variable to start correctly under
Wayland (otherwise it starts inside Xwayland and looks fuzzy and fails
to screen share):
MOZ_ENABLE_WAYLAND=1 firefox
To make the change permanent, many recipes recommend adding this to an
environment startup script:
if [ "$XDG_SESSION_TYPE" == "wayland" ]; then
export MOZ_ENABLE_WAYLAND=1
fi
At least that's the theory. In practice, Sway doesn't actually run any
startup shell script, so that can't possibly work. Furthermore,
XDG_SESSION_TYPE is not actually set when starting Sway from gdm3
which I find really confusing, and I'm not the onlyone. So
the above trick doesn't actually work, even if the environment
(XDG_SESSION_TYPE) is set correctly, because we don't have
conditionals in environment.d(5).
(Note that systemd.environment-generator(7)do support running
arbitrary commands to generate environment, but for some some do not
support user-specific configuration files... Even then it may be a
solution to have a conditional MOZ_ENABLE_WAYLAND environment, but
I'm not sure it would work because ordering between those two isn't
clear: maybe the XDG_SESSION_TYPE wouldn't be set just yet...)
At first, I made this ridiculous script to workaround those
issues. Really, it seems to me Firefox should just parse the
XDG_SESSION_TYPE variable here... but then I realized that Firefox
works fine in Xorg when the MOZ_ENABLE_WAYLAND is set.
So now I just set that variable in environment.d and It Just Works :
MOZ_ENABLE_WAYLAND=1
Screen sharing
Out of the box, screen sharing doesn't work until you install
xdg-desktop-portal-wlr or similar
(e.g. xdg-desktop-portal-gnome on GNOME). I had to reboot for the
change to take effect.
Without those tools, it shows the usual permission prompt with "Use
operating system settings" as the only choice, but when we accept...
nothing happens. After installing the portals, it actualyl works, and
works well!
This was tested in Debian bookworm/testing with Firefox ESR 102 and
Firefox 106.
Major caveat: we can only share a full screen, we can't currently
share just a window. The major upside to that is that, by default,
it streams onlyone output which is actually what I want most
of the time! See the screencast compatibility for more
information on what is supposed to work.
This is actually a huge improvement over the situation in Xorg,
where Firefox can only share a window or all monitors, which led
me to use Chromium a lot for video-conferencing. With this change, in
other words, I will not need Chromium for anything anymore, whoohoo!
If slurp, wofi, or bemenu are
installed, one of them will be used to pick the monitor to share,
which effectively acts as some minimal security measure. See
xdg-desktop-portal-wlr(1) for how to configure that.
Side note: Chrome fails to share a full screen
I was still using Google Chrome (or, more accurately, Debian's
Chromium package) for some videoconferencing. It's mainly because
Chromium was the only browser which will allow me to share only one of
my two monitors, which is extremely useful.
To start chrome with the Wayland backend, you need to use:
If it shows an ugly gray border, check the Use system title bar and
borders setting.
It can do some screensharing. Sharing a window and a tab seems to
work, but sharing a full screen doesn't: it's all black. Maybe not
ready for prime time.
And since Firefox can do what I need under Wayland now, I will not
need to fight with Chromium to work under Wayland:
apt purge chromium
Note that a similar fix was necessary for Signal Desktop, see this
commit. Basically you need to figure out a way to pass those same
flags to signal:
News: feed2exec, gnus
See Email, above, or Emacs in Editor, below.
Editor: Emacs okay-ish
Emacs is being actively ported to Wayland. According to this LWN
article, the first (partial, to Cairo) port was done in 2014 and a
working port (to GTK3) was completed in 2021, but wasn't merged until
late 2021. That is: after Emacs 28 was released (April
2022).
So we'll probably need to wait for Emacs 29 to have native Wayland
support in Emacs, which, in turn, is unlikely to arrive in time for
the Debian bookworm freeze. There are, however, unofficial
builds for both Emacs 28 and 29 provided by spwhitton which
may provide native Wayland support.
I tested the snapshot packages and they do not quite work well
enough. First off, they completely take over the builtin Emacs they
hijack the $PATH in /etc! and certain things are simply not
working in my setup. For example, this hook never gets ran on startup:
(add-hook 'after-init-hook 'server-start t)
Still, like many X11 applications, Emacs mostly works fine under
Xwayland. The clipboard works as expected, for example.
Scaling is a bit of an issue: fonts look fuzzy.
I have heard anecdotal evidence of hard lockups with Emacs running
under Xwayland as well, but haven't experienced any problem so far. I
did experience a Wayland crash with the snapshot version however.
TODO: look again at Wayland in Emacs 29.
Backups: borg
Mostly irrelevant, as I do not use a GUI.
Color theme: srcery, redshift gammastep
I am keeping Srcery as a color theme, in general.
Redshift is another story: it has no support for Wayland out of
the box, but it's apparently possible to apply a hack on the TTY
before starting Wayland, with:
redshift -m drm -PO 3000
This tip is from the arch wiki which also has other suggestions
for Wayland-based alternatives. Both KDE and GNOME have their own "red
shifters", and for wlroots-based compositors, they (currently,
Sept. 2022) list the following alternatives:
greetd and QtGreet (former in Debian, not latter, which
means we're stuck with the weird agreety which doesn't work at
all)
sddm: KDE's default, in Debian, probably heavier or as heavy as
gdm3
Terminal: xterm foot
One of the biggest question mark in this transition was what to do
about Xterm. After writing twoarticles about terminal
emulators as a professional journalist, decades of working on the
terminal, and probably using dozens of different terminal emulators,
I'm still not happy with any of them.
This is such a big topic that I actually have an entire blog post
specifically about this.
For starters, using xterm under Xwayland works well enough, although
the font scaling makes things look a bit too fuzzy.
I have also tried foot: it ... just works!
Fonts are much crisper than Xterm and Emacs. URLs are not clickable
but the URL selector (control-shift-u) is just plain
awesome (think "vimperator" for the terminal).
There's cool hack to jump between prompts.
Copy-paste works. True colors work. The word-wrapping is excellent: it
doesn't lose one byte. Emojis are nicely sized and colored. Font
resize works. There's even scroll back search
(control-shift-r).
Foot went from a question mark to being a reason to switch to Wayland,
just for this little goodie, which says a lot about the quality of
that software.
The selection clicks are a not quite what I would expect though. In
rxvt and others, you have the following patterns:
single click: reset selection, or drag to select
double: select word
triple: select quotes or line
quadruple: select line
I particularly find the "select quotes" bit useful. It seems like foot
just supports double and triple clicks, with word and line
selected. You can select a rectangle with control,. It
correctly extends the selection word-wise with right click if
double-click was first used.
One major problem with Foot is that it's a new terminal, with its own
termcap entry. Support for foot was added to ncurses in the
20210731 release, which was shipped after the current Debian
stable release (Debian bullseye, which ships 6.2+20201114-2). A
workaround for this problem is to install the foot-terminfo package
on the remote host, which is available in Debian stable.
This should eventually resolve itself, as Debian bookworm has a newer
version. Note that some corrections were also shipped in the
20211113 release, but that is also shipped in Debian bookworm.
That said, I am almost certain I will have to revert back to xterm
under Xwayland at some point in the future. Back when I was using
GNOME Terminal, it would mostly work for everything until I had to use
the serial console on a (HP ProCurve) network switch, which have a
fancy TUI that was basically unusable there. I fully expect such
problems with foot, or any other terminal than xterm, for that matter.
The foot wiki has good troubleshooting instructions as well.
Update: I did find one tiny thing to improve with foot, and it's the
default logging level which I found pretty verbose. After discussing
it with the maintainer on IRC, I submitted this patch to tweak
it, which I described like this on Mastodon:
today's reason why i will go to hell when i die (TRWIWGTHWID?): a
600-word, 63 lines commit log for a one line change:
https://codeberg.org/dnkl/foot/pulls/1215
The above list comes partly from https://arewewaylandyet.com/ and
awesome-wayland. It is likely incomplete.
I have read some good things about bemenu, fuzzel, and wofi.
A particularly tricky option is that my rofi password management
depends on xdotool for some operations. At first, I thought this was
just going to be (thankfully?) impossible, because we actually like
the idea that one app cannot send keystrokes to another. But it seems
there are actually alternatives to this, like wtype or
ydotool, the latter which requires root access. wl-ime-type
does that through the input-method-unstable-v2 protocol (sample
emoji picker, but is not packaged in Debian.
As it turns out, wtype just works as expected, and fixing this was
basically a two-line patch. Another alternative, not in Debian, is
wofi-pass.
The other problem is that I actually heavily modified rofi. I use
"modis" which are not actually implemented in wofi or tofi, so I'm
left with reinventing those wheels from scratch or using the rofi +
wayland fork... It's really too bad that fork isn't being
reintegrated...
For now, I'm actually still using rofi under Xwayland. The main
downside is that fonts are fuzzy, but it otherwise just works.
Note that wlogout could be a partial replacement (just for the
"power menu").
Image viewers: geeqie ?
I'm not very happy with geeqie in the first place, and I suspect the
Wayland switch will just make add impossible things on top of the
things I already find irritating (Geeqie doesn't support copy-pasting
images).
In practice, Geeqie doesn't seem to work so well under Wayland. The
fonts are fuzzy and the thumbnail preview just doesn't work anymore
(filed as Debian bug 1024092). It seems it also has problems
with scaling.
Alternatives:
See also this list and that list for other list of image
viewers, not necessarily ported to Wayland.
TODO: pick an alternative to geeqie, nomacs would be gorgeous if it
wouldn't be basically abandoned upstream (no release since 2020), has
an unpatchedCVE-2020-23884 since July 2020, does bad
vendoring, and is in bad shape in Debian (4 minor releases
behind).
So for now I'm still grumpily using Geeqie.
Media player: mpv, gmpc / sublime
This is basically unchanged. mpv seems to work fine under Wayland,
better than Xorg on my new laptop (as mentioned in the introduction),
and that before the version which improves Wayland support
significantly, by bringing native Pipewire support and DMA-BUF
support.
gmpc is more of a problem, mainly because it is abandoned. See
2022-08-22-gmpc-alternatives for the full discussion, one of
the alternatives there will likely support Wayland.
Finally, I might just switch to sublime-music instead... In any
case, not many changes here, thankfully.
Screensaver: xsecurelock swaylock
I was previously using xss-lock and xsecurelock as a screensaver, with
xscreensaver "hacks" as a backend for xsecurelock.
The basic screensaver in Sway seems to be built with swayidle and
swaylock. It's interesting because it's the same "split" design
as xss-lock and xsecurelock.
That, unfortunately, does not include the fancy "hacks" provided by
xscreensaver, and that is unlikely to be implemented upstream.
Other alternatives include gtklock and waylock (zig), which
do not solve that problem either.
It looks like swaylock-plugin, a swaylock fork, which at least
attempts to solve this problem, although not directly using the real
xscreensaver hacks. swaylock-effects is another attempt at this,
but it only adds more effects, it doesn't delegate the image display.
Other than that, maybe it's time to just let go of those funky
animations and just let swaylock do it's thing, which is display a
static image or just a black screen, which is fine by me.
In the end, I am just using swayidle with a configuration based on
the systemd integration wiki page but with additional tweaks from
this service, see the resulting swayidle.service file.
Interestingly, damjan also has a service for swaylock itself,
although it's not clear to me what its purpose is...
Screenshot: maim grim, pubpaste
I'm a heavy user of maim (and a package uploader in Debian). It
looks like the direct replacement to maim (and slop) is grim
(and slurp). There's also swappy which goes on top of grim
and allows preview/edit of the resulting image, nice touch (not in
Debian though).
See also awesome-wayland screenshots for other alternatives:
there are many, including X11 tools like Flameshot that also
support Wayland.
One key problem here was that I have my own screenshot / pastebin
software which will needed an update for Wayland as well. That,
thankfully, meant actually cleaning up a lot of horrible code that
involved calling xterm and xmessage for user interaction. Now,
pubpaste uses GTK for prompts and looks much better. (And before
anyone freaks out, I already had to use GTK for proper clipboard
support, so this isn't much of a stretch...)
Screen recorder: simplescreenrecorder wf-recorder
In Xorg, I have used both peek or simplescreenrecorder for
screen recordings. The former will work in Wayland, but has no
sound support. The latter has a fork with Wayland support but
it is limited and buggy ("doesn't support recording area selection and
has issues with multiple screens").
It looks like wf-recorder will just do everything correctly out
of the box, including audio support (with --audio, duh). It's also
packaged in Debian.
One has to wonder how this works while keeping the "between app
security" that Wayland promises, however... Would installing such a
program make my system less secure?
Many other options are available, see the awesome Wayland
screencasting list.
RSI: workrave nothing?
Workrave has no support for Wayland. activity watch is a
time tracker alternative, but is not a RSI watcher. KDE has
rsiwatcher, but that's a bit too much on the heavy side for my
taste.
SafeEyes looks like an alternative at first, but it has many
issues under Wayland (escape doesn't work, idle doesn't
work, it just doesn't work really). timekpr-nextcould be
an alternative as well, and has support for Wayland.
I am also considering just abandoning workrave, even if I stick with
Xorg, because it apparently introduces significant latency in the
input pipeline.
And besides, I've developed a pretty unhealthy alert fatigue with
Workrave. I have used the program for so long that my fingers know
exactly where to click to dismiss those warnings very effectively. It
makes my work just more irritating, and doesn't fix the fundamental
problem I have with computers.
Other apps
This is a constantly changing list, of course. There's a bit of a
"death by a thousand cuts" in migrating to Wayland because you realize
how many things you were using are tightly bound to X.
.Xresources - just say goodbye to that old resource system, it
was used, in my case, only for rofi, xterm, and ... Xboard!?
keyboard layout switcher: built-in to Sway since 2017 (PR
1505, 1.5rc2+), requires a small configuration change, see
this answer as well, looks something like this command:
That works refreshingly well, even better than in Xorg, I must say.
swaykbdd is an alternative that supports per-window layouts
(in Debian).
wallpaper: currently using feh, will need a replacement, TODO:
figure out something that does, like feh, a random shuffle.
swaybg just loads a single image, duh. oguri might be a
solution, but unmaintained, used here, not in
Debian. wallutils is another option, also not in
Debian. For now I just don't have a wallpaper, the background is a
solid gray, which is better than Xorg's default (which is whatever
crap was left around a buffer by the previous collection of
programs, basically)
notifications: currently using dunst in some places, which
works well in both Xorg and Wayland, not a blocker, salut a
possible alternative (not in Debian), damjan uses mako. TODO:
install dunst everywhere
nov 11 22:34:12 angela sway[298938]: 00:49:42.325 [INFO] [swaybar/tray/host.c:24] Registering Status Notifier Item ':1.47/org/ayatana/NotificationItem/nm_applet'
nov 11 22:34:12 angela sway[298938]: 00:49:42.327 [ERROR] [swaybar/tray/item.c:127] :1.47/org/ayatana/NotificationItem/nm_applet IconPixmap: No such property IconPixmap
nov 11 22:34:12 angela sway[298938]: 00:49:42.327 [ERROR] [swaybar/tray/item.c:127] :1.47/org/ayatana/NotificationItem/nm_applet AttentionIconPixmap: No such property AttentionIconPixmap
nov 11 22:34:12 angela sway[298938]: 00:49:42.327 [ERROR] [swaybar/tray/item.c:127] :1.47/org/ayatana/NotificationItem/nm_applet ItemIsMenu: No such property ItemIsMenu
nov 11 22:36:10 angela sway[313419]: info: fcft.c:838: /usr/share/fonts/truetype/dejavu/DejaVuSans.ttf: size=24.00pt/32px, dpi=96.00
... but it seems innocuous. The tray icon displays but, as stated
above, is not clickable. If you don't see the icon, check the
bar.tray_output property in the Sway config, try: tray_output *.
Note that there is currently (November 2022) a pull request to
hook up a "Tray D-Bus Menu" which, according to Reddit might
fix this, or at least be somewhat relevant.
This was the biggest irritant in my migration. I have used nmtui
to connect to new Wifi hotspots or change connection settings, but
that doesn't support actions like "turn off WiFi".
I eventually fixed this by switching from py3status to
waybar.
window switcher: in i3 I was using this bespoke i3-focus
script, which doesn't work under Sway, swayr an option, not in
Debian. So I put together this other bespoke hack from
multiple sources, which works.
PDF viewer: currently using atril (which supports Wayland), could
also just switch to zatura/mupdf permanently, see also calibre
for a discussion on document viewers
More X11 / Wayland equivalents
For all the tools above, it's not exactly clear what options exist in
Wayland, or when they do, which one should be used. But for some basic
tools, it seems the options are actually quite clear. If that's the
case, they should be listed here:
Note that arandr and autorandr are not directly part of
X. arewewaylandyet.com refers to a few alternatives. We suggest
wdisplays and kanshi above (see also this service
file) but wallutils can also do the autorandr stuff, apparently,
and nwg-displays can do the arandr part. Neither are packaged in
Debian yet.
So I have tried wdisplays and it Just Works, and well. The UI even
looks better and more usable than arandr, so another clean win from
Wayland here.
TODO: test kanshi as a autorandr replacement
Other issues
systemd integration
I've had trouble getting session startup to work. This is partly
because I had a kind of funky system to start my session in the first
place. I used to have my whole session started from .xsession like
this:
But obviously, the xsession.target is not started by the Sway
session. It seems to just start a default.target, which is really
not what we want because we want to associate the services directly
with the graphical-session.target, so that they don't start when
logging in over (say) SSH.
damjan on #debian-systemd showed me his sway-setup which
features systemd integration. It involves starting a different session
in a completely new .desktop file. That work was submitted
upstream but refused on the grounds that "I'd rather not give a
preference to any particular init system." Another PR was
abandoned because "restarting sway does not makes sense: that
kills everything".
The work was therefore moved to the wiki.
So. Not a great situation. The upstream wikisystemd
integration suggests starting the systemd target from within
Sway, which has all sorts of problems:
you don't get Sway logs anywhere
control groups are all messed up
I have done a lot of work trying to figure this out, but I remember
that starting systemd from Sway didn't actually work for me: my
previously configured systemd units didn't correctly start, and
especially not with the right $PATH and environment.
So I went down that rabbit hole and managed to correctly configure
Sway to be started from the systemd --user session.
I have partly followed the wiki but also picked ideas from damjan's
sway-setup and xdbob's sway-services. Another option is
uwsm (not in Debian).
This is the config I have in .config/systemd/user/:
You will also need at least part of my sway/config, which
sends the systemd notification (because, no, Sway doesn't support any
sort of readiness notification, that would be too easy). And you might
like to see my swayidle-config while you're there.
Finally, you need to hook this up somehow to the login manager. This
is typically done with a desktop file, so drop
sway-session.desktop in /usr/share/wayland-sessions and
sway-user-service somewhere in your $PATH (typically
/usr/bin/sway-user-service).
The session then looks something like this:
Environment propagation
At first, my terminals and rofi didn't have the right $PATH, which
broke a lot of my workflow. It's hard to tell exactly how Wayland
gets started or where to inject environment. This discussion
suggests a few alternatives and this Debian bug report discusses
this issue as well.
I eventually picked environment.d(5) since I already manage my user
session with systemd, and it fixes a bunch of other problems. I used
to have a .shenv that I had to manually source everywhere. The only
problem with that approach is that it doesn't support conditionals,
but that's something that's rarely needed.
Pipewire
This is a whole topic onto itself, but migrating to Wayland also
involves using Pipewire if you want screen sharing to work. You
can actually keep using Pulseaudio for audio, that said, but that
migration is actually something I've wanted to do anyways: Pipewire's
design seems much better than Pulseaudio, as it folds in JACK
features which allows for pretty neat tricks. (Which I should probably
show in a separate post, because this one is getting rather long.)
I first tried this migration in Debian bullseye, and it didn't work
very well. Ardour would fail to export tracks and I would get
into weird situations where streams would just drop mid-way.
A particularly funny incident is when I was in a meeting and I
couldn't hear my colleagues speak anymore (but they could) and I went
on blabbering on my own for a solid 5 minutes until I realized what
was going on. By then, people had tried numerous ways of letting me
know that something was off, including (apparently) coughing, saying
"hello?", chat messages, IRC, and so on, until they just gave up and
left.
I suspect that was also a Pipewire bug, but it could also have been
that I muted the tab by error, as I recently learned that clicking on
the little tiny speaker icon on a tab mutes that tab. Since the tab
itself can get pretty small when you have lots of them, it's actually
quite frequently that I mistakenly mute tabs.
Anyways. Point is: I already knew how to make the migration, and I had
already documented how to make the change in Puppet. It's
basically:
An optional (but key, IMHO) configuration you should also make is to
"switch on connect", which will make your Bluetooth or USB headset
automatically be the default route for audio, when connected. In
~/.config/pipewire/pipewire-pulse.conf.d/autoconnect.conf:
See the excellent as usual Arch wiki page about Pipewire for
that trick and more information about Pipewire. Note that you must
not put the file in ~/.config/pipewire/pipewire.conf (or
pipewire-pulse.conf, maybe) directly, as that will break your
setup. If you want to add to that file, first copy the template from
/usr/share/pipewire/pipewire-pulse.conf first.
So far I'm happy with Pipewire in bookworm, but I've heard mixed
reports from it. I have high hopes it will become the standard media
server for Linux in the coming months or years, which is great because
I've been (rather boldly, I admit) on the record saying I don't like
PulseAudio.
Rereading this now, I feel it might have been a little unfair, as
"over-engineered and tries to do too many things at once" applies
probably even more to Pipewire than PulseAudio (since it also handles
video dispatching).
That said, I think Pipewire took the right approach by implementing
existing interfaces like Pulseaudio and JACK. That way we're not
adding a third (or fourth?) way of doing audio in Linux; we're just
making the server better.
Keypress drops
Sometimes I lose keyboard presses. This correlates with the following
warning from Sway:
d c 06 10:36:31 curie sway[343384]: 23:32:14.034 [ERROR] [wlr] [libinput] event5 - SONiX USB Keyboard: client bug: event processing lagging behind by 37ms, your system is too slow
... and corresponds to an open bug report in Sway. It seems the
"system is too slow" should really be "your compositor is too slow"
which seems to be the case here on this older system
(curie). It doesn't happen often, but it does happen,
particularly when a bunch of busy processes start in parallel (in my
case: a linter running inside a container and notmuch new).
The proposed fix for this in Sway is to gain real time privileges
and add the CAP_SYS_NICE capability to the binary. We'll see how
that goes in Debian once 1.8 gets released and shipped.
Improvements over i3
Tiling improvements
There's a lot of improvements Sway could bring over using plain
i3. There are pretty neat auto-tilers that could replicate the
configurations I used to have in Xmonad or Awesome, see:
Display latency tweaks
TODO: You can tweak the display latency in wlroots compositors with the
max_render_time parameter, possibly getting lower latency than
X11 in the end.
Sound/brightness changes notifications
TODO: Avizo can display a pop-up to give feedback on volume and
brightness changes. Not in Debian. Other alternatives include
SwayOSD and sway-nc, also not in Debian.
Debugging tricks
The xeyes (in the x11-apps package) will run in Wayland, and can
actually be used to easily see if a given window is also in
Wayland. If the "eyes" follow the cursor, the app is actually running
in xwayland, so not natively in Wayland.
Another way to see what is using Wayland in Sway is with the command:
Conclusion
In general, this took me a long time, but it mostly works. The tray
icon situation is pretty frustrating, but there's a workaround and I
have high hopes it will eventually fix itself. I'm also actually
worried about the DisplayLink support because I eventually want to
be using this, but hopefully that's another thing that will hopefully
fix itself before I need it.
A word on the security model
I'm kind of worried about all the hacks that have been added to
Wayland just to make things work. Pretty much everywhere we need to,
we punched a hole in the security model:
windows can overlay on top of each other (so one app could, for
example, spoof a password dialog, through the layer-shell
protocol)
Wikipedia describes the security properties of Wayland as it
"isolates the input and output of every window, achieving
confidentiality, integrity and availability for both." I'm not sure
those are actually realized in the actual implementation, because of
all those holes punched in the design, at least in Sway. For example,
apparently the GNOME compositor doesn't have the virtual-keyboard
protocol, but they do have (another?!) text input protocol.
Wayland does offer a better basis to implement such a system,
however. It feels like the Linux applications security model lacks
critical decision points in the UI, like the user approving "yes, this
application can share my screen now". Applications themselves might
have some of those prompts, but it's not mandatory, and that is
worrisome.
In my tubman setup, I started using ZFS on an old server
I had lying around. The machine is really old though (2011!) and it
"feels" pretty slow. I want to see how much of that is ZFS and how
much is the machine. Synthetic benchmarks show that ZFS may be slower
than mdadm in RAID-10 or RAID-6 configuration, so I want to confirm
that on a live workload: my workstation. Plus, I want easy, regular,
high performance backups (with send/receive snapshots) and there's no
way I'm going to use BTRFS because I find
it too confusing and unreliable.
So off we go.
Installation
Since this is a conversion (and not a new install), our procedure is
slightly different than the official documentation but otherwise
it's pretty much in the same spirit: we're going to use ZFS for
everything, including the root filesystem.
So, install the required packages, on the current system:
root@curie:/home/anarcat# sgdisk -p /dev/sdc
Disk /dev/sdc: 1953525168 sectors, 931.5 GiB
Model: ESD-S1C
Sector size (logical/physical): 512/512 bytes
Disk identifier (GUID): [REDACTED]
Partition table holds up to 128 entries
Main partition table begins at sector 2 and ends at sector 33
First usable sector is 34, last usable sector is 1953525134
Partitions will be aligned on 16-sector boundaries
Total free space is 14 sectors (7.0 KiB)
Number Start (sector) End (sector) Size Code Name
1 48 2047 1000.0 KiB EF02
2 2048 1050623 512.0 MiB EF00
3 1050624 3147775 1024.0 MiB BF01
4 3147776 1953525134 930.0 GiB BF00
Unfortunately, we can't be sure of the sector size here, because the
USB controller is probably lying to us about it. Normally, this
smartctl command should tell us the sector size as well:
root@curie:~# smartctl -i /dev/sdb -qnoserial
smartctl 7.2 2020-12-30 r5155 [x86_64-linux-5.10.0-14-amd64] (local build)
Copyright (C) 2002-20, Bruce Allen, Christian Franke, www.smartmontools.org
=== START OF INFORMATION SECTION ===
Model Family: Western Digital Black Mobile
Device Model: WDC WD10JPLX-00MBPT0
Firmware Version: 01.01H01
User Capacity: 1 000 204 886 016 bytes [1,00 TB]
Sector Sizes: 512 bytes logical, 4096 bytes physical
Rotation Rate: 7200 rpm
Form Factor: 2.5 inches
Device is: In smartctl database [for details use: -P show]
ATA Version is: ATA8-ACS T13/1699-D revision 6
SATA Version is: SATA 3.0, 6.0 Gb/s (current: 6.0 Gb/s)
Local Time is: Tue May 17 13:33:04 2022 EDT
SMART support is: Available - device has SMART capability.
SMART support is: Enabled
Above is the example of the builtin HDD drive. But the SSD device
enclosed in that USB controller doesn't support SMART commands,
so we can't trust that it really has 512 bytes sectors.
This matters because we need to tweak the ashift value
correctly. We're going to go ahead the SSD drive has the common 4KB
settings, which means ashift=12.
Note here that we are not creating a separate partition for
swap. Swap on ZFS volumes (AKA "swap on ZVOL") can trigger lockups and
that issue is still not fixed upstream. Ubuntu recommends using a
separate partition for swap instead. But since this is "just" a
workstation, we're betting that we will not suffer from this problem,
after hearing a report from another Debian developer running this
setup on their workstation successfully.
We do not recommend this setup though. In fact, if I were to redo this
partition scheme, I would probably use LUKS encryption and setup a
dedicated swap partition, as I had problems with ZFS encryption as
well.
Creating pools
ZFS pools are somewhat like "volume groups" if you are familiar with
LVM, except they obviously also do things like RAID-10. (Even though
LVM can technically also do RAID, people typically use mdadm
instead.)
In any case, the guide suggests creating two different pools here:
one, in cleartext, for boot, and a separate, encrypted one, for the
rest. Technically, the boot partition is required because the Grub
bootloader only supports readonly ZFS pools, from what I
understand. But I'm a little out of my depth here and just following
the guide.
Boot pool creation
This creates the boot pool in readonly mode with features that grub
supports:
-O encryption=on -O keylocation=prompt -O keyformat=passphrase:
encryption, prompt for a password, default algorithm is
aes-256-gcm, explicit in the guide, made implicit here
-O acltype=posixacl -O xattr=sa: enable ACLs, with better
performance (not enabled by default)
-O dnodesize=auto: related to extended attributes, less
compatibility with other implementations
-O compression=zstd: enable zstd compression, can be
disabled/enabled by dataset to with zfs set compression=off
rpool/example
-O relatime=on: classic atime optimisation, another that could
be used on a busy server is atime=off
-O canmount=off: do not make the pool mount automatically with
mount -a?
-O mountpoint=/ -R /mnt: mount pool on / in the future, but
/mnt for now
Those settings are all available in zfsprops(8). Other flags are
defined in zpool-create(8). The reasoning behind them is also
explained in the upstream guide and some also in [the Debian
wiki][]. Those flags were actually not used:
-O normalization=formD: normalize file names on comparisons (not
storage), implies utf8only=on, which is a bad idea (and
effectively meant my first sync failed to copy some files,
including this folder from a supysonic checkout). and this
cannot be changed after the filesystem is created. bad, bad, bad.
Side note about single-disk pools
Also note that we're living dangerously here: single-disk ZFS pools
are rumoured to be more dangerous than not running ZFS at all. The
choice quote from this article is:
[...] any error can be detected, but cannot be corrected. This
sounds like an acceptable compromise, but its actually not. The
reason its not is that ZFS' metadata cannot be allowed to be
corrupted. If it is it is likely the zpool will be impossible to
mount (and will probably crash the system once the corruption is
found). So a couple of bad sectors in the right place will mean that
all data on the zpool will be lost. Not some, all. Also there's no
ZFS recovery tools, so you cannot recover any data on the drives.
Compared with (say) ext4, where a single disk error can recovered,
this is pretty bad. But we are ready to live with this with the idea
that we'll have hourly offline snapshots that we can easily recover
from. It's trade-off. Also, we're running this on a NVMe/M.2 drive
which typically just blinks out of existence completely, and doesn't
"bit rot" the way a HDD would.
Also, the FreeBSD handbook quick start doesn't have any warnings
about their first example, which is with a single disk. So I am
reassured at least.
Creating mount points
Next we create the actual filesystems, known as "datasets" which are
the things that get mounted on mountpoint and hold the actual files.
Note that it's unclear to me why those datasets are necessary, but
they seem common practice, also used in this FreeBSD
example. The OpenZFS guide mentions the Solaris upgrades and
Ubuntu's zsys that use that container for upgrades and rollbacks.
This blog post seems to explain a bit the layout behind the
installer.
this creates the actual boot and root filesystems:
Notice here a peculiarity: we must create rpool/var/lib to
create rpool/var/lib/docker otherwise we get this error:
cannot create 'rpool/var/lib/docker': parent does not exist
... and no, just creating /mnt/var/lib doesn't fix that
problem. In fact, it makes things even more confusing because an
existing directory shadows a mountpoint, which is the opposite of
how things normally work.
Also note that you will probably need to change storage driver in
Docker, see the zfs-driver documentation for details but,
basically, I did:
Now that we have everything setup and mounted, let's copy all files
over.
Copying files
This is a list of all the mounted filesystems
for fs in /boot/ /boot/efi/ / /home/; do
echo "syncing $fs to /mnt$fs..." &&
rsync -aSHAXx --info=progress2 --delete $fs /mnt$fs
done
You can check that the list is correct with:
mount -l -t ext4,btrfs,vfat awk ' print $3 '
Note that we skip /srv as it's on a different disk.
On the first run, we had:
root@curie:~# for fs in /boot/ /boot/efi/ / /home/; do
echo "syncing $fs to /mnt$fs..." &&
rsync -aSHAXx --info=progress2 $fs /mnt$fs
done
syncing /boot/ to /mnt/boot/...
0 0% 0.00kB/s 0:00:00 (xfr#0, to-chk=0/299)
syncing /boot/efi/ to /mnt/boot/efi/...
16,831,437 100% 184.14MB/s 0:00:00 (xfr#101, to-chk=0/110)
syncing / to /mnt/...
28,019,293,280 94% 47.63MB/s 0:09:21 (xfr#703710, ir-chk=6748/839220)rsync: [generator] delete_file: rmdir(var/lib/docker) failed: Device or resource busy (16)
could not make way for new symlink: var/lib/docker
34,081,267,990 98% 50.71MB/s 0:10:40 (xfr#736577, to-chk=0/867732)
rsync error: some files/attrs were not transferred (see previous errors) (code 23) at main.c(1333) [sender=3.2.3]
syncing /home/ to /mnt/home/...
rsync: [sender] readlink_stat("/home/anarcat/.fuse") failed: Permission denied (13)
24,456,268,098 98% 68.03MB/s 0:05:42 (xfr#159867, ir-chk=6875/172377)
file has vanished: "/home/anarcat/.cache/mozilla/firefox/s2hwvqbu.quantum/cache2/entries/B3AB0CDA9C4454B3C1197E5A22669DF8EE849D90"
199,762,528,125 93% 74.82MB/s 0:42:26 (xfr#1437846, ir-chk=1018/1983979)rsync: [generator] recv_generator: mkdir "/mnt/home/anarcat/dist/supysonic/tests/assets/\#346" failed: Invalid or incomplete multibyte or wide character (84)
*** Skipping any contents from this failed directory ***
315,384,723,978 96% 76.82MB/s 1:05:15 (xfr#2256473, to-chk=0/2993950)
rsync error: some files/attrs were not transferred (see previous errors) (code 23) at main.c(1333) [sender=3.2.3]
Note the failure to transfer that supysonic file? It turns out they
had a weird filename in their source tree, since then removed,
but still it showed how the utf8only feature might not be such a bad
idea. At this point, the procedure was restarted all the way back to
"Creating pools", after unmounting all ZFS filesystems (umount
/mnt/run /mnt/boot/efi && umount -t zfs -a) and destroying the pool,
which, surprisingly, doesn't require any confirmation (zpool destroy
rpool).
The second run was cleaner:
root@curie:~# for fs in /boot/ /boot/efi/ / /home/; do
echo "syncing $fs to /mnt$fs..." &&
rsync -aSHAXx --info=progress2 --delete $fs /mnt$fs
done
syncing /boot/ to /mnt/boot/...
0 0% 0.00kB/s 0:00:00 (xfr#0, to-chk=0/299)
syncing /boot/efi/ to /mnt/boot/efi/...
0 0% 0.00kB/s 0:00:00 (xfr#0, to-chk=0/110)
syncing / to /mnt/...
28,019,033,070 97% 42.03MB/s 0:10:35 (xfr#703671, ir-chk=1093/833515)rsync: [generator] delete_file: rmdir(var/lib/docker) failed: Device or resource busy (16)
could not make way for new symlink: var/lib/docker
34,081,807,102 98% 44.84MB/s 0:12:04 (xfr#736580, to-chk=0/867723)
rsync error: some files/attrs were not transferred (see previous errors) (code 23) at main.c(1333) [sender=3.2.3]
syncing /home/ to /mnt/home/...
rsync: [sender] readlink_stat("/home/anarcat/.fuse") failed: Permission denied (13)
IO error encountered -- skipping file deletion
24,043,086,450 96% 62.03MB/s 0:06:09 (xfr#151819, ir-chk=15117/172571)
file has vanished: "/home/anarcat/.cache/mozilla/firefox/s2hwvqbu.quantum/cache2/entries/4C1FDBFEA976FF924D062FB990B24B897A77B84B"
315,423,626,507 96% 67.09MB/s 1:14:43 (xfr#2256845, to-chk=0/2994364)
rsync error: some files/attrs were not transferred (see previous errors) (code 23) at main.c(1333) [sender=3.2.3]
Also note the transfer speed: we seem capped at 76MB/s, or
608Mbit/s. This is not as fast as I was expecting: the USB connection
seems to be at around 5Gbps:
anarcat@curie:~$ lsusb -tv head -4
/: Bus 02.Port 1: Dev 1, Class=root_hub, Driver=xhci_hcd/6p, 5000M
ID 1d6b:0003 Linux Foundation 3.0 root hub
__ Port 1: Dev 4, If 0, Class=Mass Storage, Driver=uas, 5000M
ID 0b05:1932 ASUSTek Computer, Inc.
So it shouldn't cap at that speed. It's possible the USB adapter is
failing to give me the full speed though. It's not the M.2 SSD drive
either, as that has a ~500MB/s bandwidth, acccording to its spec.
At this point, we're about ready to do the final configuration. We
drop to single user mode and do the rest of the procedure. That used
to be shutdown now, but it seems like the systemd switch broke that,
so now you can reboot into grub and pick the "recovery"
option. Alternatively, you might try systemctl rescue, as I found
out.
I also wanted to copy the drive over to another new NVMe drive, but
that failed: it looks like the USB controller I have doesn't work with
older, non-NVME drives.
Boot configuration
Now we need to enter the new system to rebuild the boot loader and
initrd and so on.
First, we bind mounts and chroot into the ZFS disk:
mount --rbind /dev /mnt/dev &&
mount --rbind /proc /mnt/proc &&
mount --rbind /sys /mnt/sys &&
chroot /mnt /bin/bash
Next we add an extra service that imports the bpool on boot, to make
sure it survives a zpool.cache destruction:
I had to trim down /etc/fstab and /etc/crypttab to only contain
references to the legacy filesystems (/srv is still BTRFS!).
If we don't already have a tmpfs defined in /etc/fstab:
Strangely, that's not exactly what the author, Jim Salter, did in
his actual test bench used in the ZFS benchmarking
article. The first thing is there's no read test at all, which is
already pretty strange. But also it doesn't include stuff like
dropping caches or repeating results.
So here's my variation, which i called fio-ars-bench.sh for
now. It just batches a bunch of fio tests, one by one, 60 seconds
each. It should take about 12 minutes to run, as there are 3 pair of
tests, read/write, with and without async.
My bias, before building, running and analysing those results is that
ZFS should outperform the traditional stack on writes, but possibly
not on reads. It's also possible it outperforms it on both, because
it's a newer drive. A new test might be possible with a new external
USB drive as well, although I doubt I will find the time to do this.
Results
All tests were done on WD blue SN550 drives, which claims to be
able to push 2400MB/s read and 1750MB/s write. An extra drive was
bought to move the LVM setup from a WDC WDS500G1B0B-00AS40 SSD, a WD
blue M.2 2280 SSD that was at least 5 years old, spec'd at 560MB/s
read, 530MB/s write. Benchmarks were done on the M.2 SSD drive but
discarded so that the drive difference is not a factor in the test.
In practice, I'm going to assume we'll never reach those numbers
because we're not actually NVMe (this is an old workstation!) so the
bottleneck isn't the disk itself. For our purposes, it might still
give us useful results.
Rescue test, LUKS/LVM/ext4
Those tests were performed with everything shutdown, after either
entering the system in rescue mode, or by reaching that target with:
systemctl rescue
The network might have been started before or after the test as well:
systemctl start systemd-networkd
So it should be fairly reliable as basically nothing else is running.
Raw numbers, from the ?job-curie-lvm.log, converted to MiB/s and
manually merged:
test
read I/O
read IOPS
write I/O
write IOPS
rand4k4g1x
39.27
10052
212.15
54310
rand4k4g1x--fsync=1
39.29
10057
2.73
699
rand64k256m16x
1297.00
20751
1068.57
17097
rand64k256m16x--fsync=1
1290.90
20654
353.82
5661
rand1m16g1x
315.15
315
563.77
563
rand1m16g1x--fsync=1
345.88
345
157.01
157
Peaks are at about 20k IOPS and ~1.3GiB/s read, 1GiB/s write in the
64KB blocks with 16 jobs.
Slowest is the random 4k block sync write at an abysmal 3MB/s and 700
IOPS The 1MB read/write tests have lower IOPS, but that is expected.
Rescue test, ZFS
This test was also performed in rescue mode.
Raw numbers, from the ?job-curie-zfs.log, converted to MiB/s and
manually merged:
test
read I/O
read IOPS
write I/O
write IOPS
rand4k4g1x
77.20
19763
27.13
6944
rand4k4g1x--fsync=1
76.16
19495
6.53
1673
rand64k256m16x
1882.40
30118
70.58
1129
rand64k256m16x--fsync=1
1865.13
29842
71.98
1151
rand1m16g1x
921.62
921
102.21
102
rand1m16g1x--fsync=1
908.37
908
64.30
64
Peaks are at 1.8GiB/s read, also in the 64k job like above, but much
faster. The write is, as expected, much slower at 70MiB/s (compared
to 1GiB/s!), but it should be noted the sync write doesn't degrade
performance compared to async writes (although it's still below the
LVM 300MB/s).
Conclusions
Really, ZFS has trouble performing in all write conditions. The
random 4k sync write test is the only place where ZFS outperforms
LVM in writes, and barely (7MiB/s vs 3MiB/s). Everywhere else, writes
are much slower, sometimes by an order of magnitude.
And before some ZFS zealot jumps in talking about the SLOG or some
other cache that could be added to improved performance, I'll remind
you that those numbers are on a bare bones NVMe drive, pretty much as
fast storage as you can find on this machine. Adding another NVMe
drive as a cache probably will not improve write performance here.
Still, those are very different results than the tests performed by
Salter which shows ZFS beating traditional configurations in all
categories but uncached 4k reads (not writes!). That said, those tests
are very different from the tests I performed here, where I test
writes on a single disk, not a RAID array, which might explain the
discrepancy.
Also, note that neither LVM or ZFS manage to reach the 2400MB/s read
and 1750MB/s write performance specification. ZFS does manage to reach
82% of the read performance (1973MB/s) and LVM 64% of the write
performance (1120MB/s). LVM hits 57% of the read performance and ZFS
hits barely 6% of the write performance.
Overall, I'm a bit disappointed in the ZFS write performance here, I
must say. Maybe I need to tweak the record size or some other ZFS
voodoo, but I'll note that I didn't have to do any such configuration
on the other side to kick ZFS in the pants...
Real world experience
This section document not synthetic backups, but actual real world
workloads, comparing before and after I switched my workstation to
ZFS.
Docker performance
I had the feeling that running some git hook (which was firing a
Docker container) was "slower" somehow. It seems that, at runtime, ZFS
backends are significant slower than their overlayfs/ext4 equivalent:
May 16 14:42:52 curie systemd[1]: home-docker-overlay2-17e4d24228decc2d2d493efc401dbfb7ac29739da0e46775e122078d9daf3e87\x2dinit-merged.mount: Succeeded.
May 16 14:42:52 curie systemd[5161]: home-docker-overlay2-17e4d24228decc2d2d493efc401dbfb7ac29739da0e46775e122078d9daf3e87\x2dinit-merged.mount: Succeeded.
May 16 14:42:52 curie systemd[1]: home-docker-overlay2-17e4d24228decc2d2d493efc401dbfb7ac29739da0e46775e122078d9daf3e87-merged.mount: Succeeded.
May 16 14:42:53 curie dockerd[1723]: time="2022-05-16T14:42:53.087219426-04:00" level=info msg="starting signal loop" namespace=moby path=/run/docker/containerd/daemon/io.containerd.runtime.v2.task/moby/af22586fba07014a4d10ab19da10cf280db7a43cad804d6c1e9f2682f12b5f10 pid=151170
May 16 14:42:53 curie systemd[1]: Started libcontainer container af22586fba07014a4d10ab19da10cf280db7a43cad804d6c1e9f2682f12b5f10.
May 16 14:42:54 curie systemd[1]: docker-af22586fba07014a4d10ab19da10cf280db7a43cad804d6c1e9f2682f12b5f10.scope: Succeeded.
May 16 14:42:54 curie dockerd[1723]: time="2022-05-16T14:42:54.047297800-04:00" level=info msg="shim disconnected" id=af22586fba07014a4d10ab19da10cf280db7a43cad804d6c1e9f2682f12b5f10
May 16 14:42:54 curie dockerd[998]: time="2022-05-16T14:42:54.051365015-04:00" level=info msg="ignoring event" container=af22586fba07014a4d10ab19da10cf280db7a43cad804d6c1e9f2682f12b5f10 module=libcontainerd namespace=moby topic=/tasks/delete type="*events.TaskDelete"
May 16 14:42:54 curie systemd[2444]: run-docker-netns-f5453c87c879.mount: Succeeded.
May 16 14:42:54 curie systemd[5161]: run-docker-netns-f5453c87c879.mount: Succeeded.
May 16 14:42:54 curie systemd[2444]: home-docker-overlay2-17e4d24228decc2d2d493efc401dbfb7ac29739da0e46775e122078d9daf3e87-merged.mount: Succeeded.
May 16 14:42:54 curie systemd[5161]: home-docker-overlay2-17e4d24228decc2d2d493efc401dbfb7ac29739da0e46775e122078d9daf3e87-merged.mount: Succeeded.
May 16 14:42:54 curie systemd[1]: run-docker-netns-f5453c87c879.mount: Succeeded.
May 16 14:42:54 curie systemd[1]: home-docker-overlay2-17e4d24228decc2d2d493efc401dbfb7ac29739da0e46775e122078d9daf3e87-merged.mount: Succeeded.
Translating this:
container setup: ~1 second
container runtime: ~1 second
container teardown: ~1 second
total runtime: 2-3 seconds
Obviously, those timestamps are not quite accurate enough to make
precise measurements...
After I switched to ZFS:
mai 30 15:31:39 curie systemd[1]: var-lib-docker-zfs-graph-41ce08fb7a1d3a9c101694b82722f5621c0b4819bd1d9f070933fd1e00543cdf\x2dinit.mount: Succeeded.
mai 30 15:31:39 curie systemd[5287]: var-lib-docker-zfs-graph-41ce08fb7a1d3a9c101694b82722f5621c0b4819bd1d9f070933fd1e00543cdf\x2dinit.mount: Succeeded.
mai 30 15:31:40 curie systemd[1]: var-lib-docker-zfs-graph-41ce08fb7a1d3a9c101694b82722f5621c0b4819bd1d9f070933fd1e00543cdf.mount: Succeeded.
mai 30 15:31:40 curie systemd[5287]: var-lib-docker-zfs-graph-41ce08fb7a1d3a9c101694b82722f5621c0b4819bd1d9f070933fd1e00543cdf.mount: Succeeded.
mai 30 15:31:41 curie dockerd[3199]: time="2022-05-30T15:31:41.551403693-04:00" level=info msg="starting signal loop" namespace=moby path=/run/docker/containerd/daemon/io.containerd.runtime.v2.task/moby/42a1a1ed5912a7227148e997f442e7ab2e5cc3558aa3471548223c5888c9b142 pid=141080
mai 30 15:31:41 curie systemd[1]: run-docker-runtime\x2drunc-moby-42a1a1ed5912a7227148e997f442e7ab2e5cc3558aa3471548223c5888c9b142-runc.ZVcjvl.mount: Succeeded.
mai 30 15:31:41 curie systemd[5287]: run-docker-runtime\x2drunc-moby-42a1a1ed5912a7227148e997f442e7ab2e5cc3558aa3471548223c5888c9b142-runc.ZVcjvl.mount: Succeeded.
mai 30 15:31:41 curie systemd[1]: Started libcontainer container 42a1a1ed5912a7227148e997f442e7ab2e5cc3558aa3471548223c5888c9b142.
mai 30 15:31:45 curie systemd[1]: docker-42a1a1ed5912a7227148e997f442e7ab2e5cc3558aa3471548223c5888c9b142.scope: Succeeded.
mai 30 15:31:45 curie dockerd[3199]: time="2022-05-30T15:31:45.883019128-04:00" level=info msg="shim disconnected" id=42a1a1ed5912a7227148e997f442e7ab2e5cc3558aa3471548223c5888c9b142
mai 30 15:31:45 curie dockerd[1726]: time="2022-05-30T15:31:45.883064491-04:00" level=info msg="ignoring event" container=42a1a1ed5912a7227148e997f442e7ab2e5cc3558aa3471548223c5888c9b142 module=libcontainerd namespace=moby topic=/tasks/delete type="*events.TaskDelete"
mai 30 15:31:45 curie systemd[1]: run-docker-netns-e45f5cf5f465.mount: Succeeded.
mai 30 15:31:45 curie systemd[5287]: run-docker-netns-e45f5cf5f465.mount: Succeeded.
mai 30 15:31:45 curie systemd[1]: var-lib-docker-zfs-graph-41ce08fb7a1d3a9c101694b82722f5621c0b4819bd1d9f070933fd1e00543cdf.mount: Succeeded.
mai 30 15:31:45 curie systemd[5287]: var-lib-docker-zfs-graph-41ce08fb7a1d3a9c101694b82722f5621c0b4819bd1d9f070933fd1e00543cdf.mount: Succeeded.
That's double or triple the run time, from 2 seconds to 6
seconds. Most of the time is spent in run time, inside the
container. Here's the breakdown:
container setup: ~2 seconds
container run: ~4 seconds
container teardown: ~1 second
total run time: about ~6-7 seconds
That's a two- to three-fold increase! Clearly something is going on
here that I should tweak. It's possible that code path is less
optimized in Docker. I also worry about podman, but apparently it
also supports ZFS backends. Possibly it would perform better, but
at this stage I wouldn't have a good comparison: maybe it would have
performed better on non-ZFS as well...
Interactivity
While doing the offsite backups (below), the system became somewhat
"sluggish". I felt everything was slow, and I estimate it introduced
~50ms latency in any input device.
Arguably, those are all USB and the external drive was connected
through USB, but I suspect the ZFS drivers are not as well tuned with
the scheduler as the regular filesystem drivers...
Recovery procedures
For test purposes, I unmounted all systems during the procedure:
umount /mnt/boot/efi /mnt/boot/run
umount -a -t zfs
zpool export -a
And disconnected the drive, to see how I would recover this system
from another Linux system in case of a total motherboard failure.
To import an existing pool, plug the device, then import the pool with
an alternate root, so it doesn't mount over your existing filesystems,
then you mount the root filesystem and all the others:
zpool import -l -a -R /mnt &&
zfs mount rpool/ROOT/debian &&
zfs mount -a &&
mount /dev/sdc2 /mnt/boot/efi &&
mount -t tmpfs tmpfs /mnt/run &&
mkdir /mnt/run/lock
Offsite backup
Part of the goal of using ZFS is to simplify and harden backups. I
wanted to experiment with shorter recovery times specifically both
point in time recovery objective and recovery time objective
and faster incremental backups.
This is, therefore, part of my backup services.
This section documents how an external NVMe enclosure was setup in a
pool to mirror the datasets from my workstation.
The final setup should include syncoid copying datasets to the backup
server regularly, but I haven't finished that configuration yet.
Partitioning
The above partitioning procedure used sgdisk, but I couldn't figure
out how to do this with sgdisk, so this uses sfdisk to dump the
partition from the first disk to an external, identical drive:
First sync
I used syncoid to copy all pools over to the external device. syncoid
is a thing that's part of the sanoid project which is
specifically designed to sync snapshots between pool, typically over
SSH links but it can also operate locally.
The sanoid command had a --readonly argument to simulate changes,
but syncoid didn't so I tried to fix that with an upstream PR.
It seems it would be better to do this by hand, but this was much
easier. The full first sync was:
root@curie:/home/anarcat# ./bin/syncoid -r bpool bpool-tubman
CRITICAL ERROR: Target bpool-tubman exists but has no snapshots matching with bpool!
Replication to target would require destroying existing
target. Cowardly refusing to destroy your existing target.
NOTE: Target bpool-tubman dataset is < 64MB used - did you mistakenly run
zfs create bpool-tubman on the target? ZFS initial
replication must be to a NON EXISTENT DATASET, which will
then be CREATED BY the initial replication process.
INFO: Sending oldest full snapshot bpool/BOOT@test (~ 42 KB) to new target filesystem:
44.2KiB 0:00:00 [4.19MiB/s] [========================================================================================================================] 103%
INFO: Updating new target filesystem with incremental bpool/BOOT@test ... syncoid_curie_2022-05-30:12:50:39 (~ 4 KB):
2.13KiB 0:00:00 [ 114KiB/s] [===============================================================> ] 53%
INFO: Sending oldest full snapshot bpool/BOOT/debian@install (~ 126.0 MB) to new target filesystem:
126MiB 0:00:00 [ 308MiB/s] [=======================================================================================================================>] 100%
INFO: Updating new target filesystem with incremental bpool/BOOT/debian@install ... syncoid_curie_2022-05-30:12:50:39 (~ 113.4 MB):
113MiB 0:00:00 [ 315MiB/s] [=======================================================================================================================>] 100%
root@curie:/home/anarcat# ./bin/syncoid -r rpool rpool-tubman
CRITICAL ERROR: Target rpool-tubman exists but has no snapshots matching with rpool!
Replication to target would require destroying existing
target. Cowardly refusing to destroy your existing target.
NOTE: Target rpool-tubman dataset is < 64MB used - did you mistakenly run
zfs create rpool-tubman on the target? ZFS initial
replication must be to a NON EXISTENT DATASET, which will
then be CREATED BY the initial replication process.
INFO: Sending oldest full snapshot rpool/ROOT@syncoid_curie_2022-05-30:12:50:51 (~ 69 KB) to new target filesystem:
44.2KiB 0:00:00 [2.44MiB/s] [===========================================================================> ] 63%
INFO: Sending oldest full snapshot rpool/ROOT/debian@install (~ 25.9 GB) to new target filesystem:
25.9GiB 0:03:33 [ 124MiB/s] [=======================================================================================================================>] 100%
INFO: Updating new target filesystem with incremental rpool/ROOT/debian@install ... syncoid_curie_2022-05-30:12:50:52 (~ 3.9 GB):
3.92GiB 0:00:33 [ 119MiB/s] [======================================================================================================================> ] 99%
INFO: Sending oldest full snapshot rpool/home@syncoid_curie_2022-05-30:12:55:04 (~ 276.8 GB) to new target filesystem:
277GiB 0:27:13 [ 174MiB/s] [=======================================================================================================================>] 100%
INFO: Sending oldest full snapshot rpool/home/root@syncoid_curie_2022-05-30:13:22:19 (~ 2.2 GB) to new target filesystem:
2.22GiB 0:00:25 [90.2MiB/s] [=======================================================================================================================>] 100%
INFO: Sending oldest full snapshot rpool/var@syncoid_curie_2022-05-30:13:22:47 (~ 5.6 GB) to new target filesystem:
5.56GiB 0:00:32 [ 176MiB/s] [=======================================================================================================================>] 100%
INFO: Sending oldest full snapshot rpool/var/cache@syncoid_curie_2022-05-30:13:23:22 (~ 627.3 MB) to new target filesystem:
627MiB 0:00:03 [ 169MiB/s] [=======================================================================================================================>] 100%
INFO: Sending oldest full snapshot rpool/var/lib@syncoid_curie_2022-05-30:13:23:28 (~ 69 KB) to new target filesystem:
44.2KiB 0:00:00 [1.40MiB/s] [===========================================================================> ] 63%
INFO: Sending oldest full snapshot rpool/var/lib/docker@syncoid_curie_2022-05-30:13:23:28 (~ 442.6 MB) to new target filesystem:
443MiB 0:00:04 [ 103MiB/s] [=======================================================================================================================>] 100%
INFO: Sending oldest full snapshot rpool/var/lib/docker/05c0de7fabbea60500eaa495d0d82038249f6faa63b12914737c4d71520e62c5@266253254 (~ 6.3 MB) to new target filesystem:
6.49MiB 0:00:00 [12.9MiB/s] [========================================================================================================================] 102%
INFO: Updating new target filesystem with incremental rpool/var/lib/docker/05c0de7fabbea60500eaa495d0d82038249f6faa63b12914737c4d71520e62c5@266253254 ... syncoid_curie_2022-05-30:13:23:34 (~ 4 KB):
1.52KiB 0:00:00 [27.6KiB/s] [============================================> ] 38%
INFO: Sending oldest full snapshot rpool/var/lib/flatpak@syncoid_curie_2022-05-30:13:23:36 (~ 2.0 GB) to new target filesystem:
2.00GiB 0:00:17 [ 115MiB/s] [=======================================================================================================================>] 100%
INFO: Sending oldest full snapshot rpool/var/tmp@syncoid_curie_2022-05-30:13:23:55 (~ 57.0 MB) to new target filesystem:
61.8MiB 0:00:01 [45.0MiB/s] [========================================================================================================================] 108%
INFO: Clone is recreated on target rpool-tubman/var/lib/docker/ed71ddd563a779ba6fb37b3b1d0cc2c11eca9b594e77b4b234867ebcb162b205 based on rpool/var/lib/docker/05c0de7fabbea60500eaa495d0d82038249f6faa63b12914737c4d71520e62c5@266253254
INFO: Sending oldest full snapshot rpool/var/lib/docker/ed71ddd563a779ba6fb37b3b1d0cc2c11eca9b594e77b4b234867ebcb162b205@syncoid_curie_2022-05-30:13:23:58 (~ 218.6 MB) to new target filesystem:
219MiB 0:00:01 [ 151MiB/s] [=======================================================================================================================>] 100%
Funny how the CRITICAL ERROR doesn't actually stop syncoid and it
just carries on merrily doing when it's telling you it's "cowardly
refusing to destroy your existing target"... Maybe that's because my pull
request broke something though...
During the transfer, the computer was very sluggish: everything feels
like it has ~30-50ms latency extra:
anarcat@curie:sanoid$ LANG=C top -b -n 1 head -20
top - 13:07:05 up 6 days, 4:01, 1 user, load average: 16.13, 16.55, 11.83
Tasks: 606 total, 6 running, 598 sleeping, 0 stopped, 2 zombie
%Cpu(s): 18.8 us, 72.5 sy, 1.2 ni, 5.0 id, 1.2 wa, 0.0 hi, 1.2 si, 0.0 st
MiB Mem : 15898.4 total, 1387.6 free, 13170.0 used, 1340.8 buff/cache
MiB Swap: 0.0 total, 0.0 free, 0.0 used. 1319.8 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
70 root 20 0 0 0 0 S 83.3 0.0 6:12.67 kswapd0
4024878 root 20 0 282644 96432 10288 S 44.4 0.6 0:11.43 puppet
3896136 root 20 0 35328 16528 48 S 22.2 0.1 2:08.04 mbuffer
3896135 root 20 0 10328 776 168 R 16.7 0.0 1:22.93 zfs
3896138 root 20 0 10588 788 156 R 16.7 0.0 1:49.30 zfs
350 root 0 -20 0 0 0 R 11.1 0.0 1:03.53 z_rd_int
351 root 0 -20 0 0 0 S 11.1 0.0 1:04.15 z_rd_int
3896137 root 20 0 4384 352 244 R 11.1 0.0 0:44.73 pv
4034094 anarcat 30 10 20028 13960 2428 S 11.1 0.1 0:00.70 mbsync
4036539 anarcat 20 0 9604 3464 2408 R 11.1 0.0 0:00.04 top
352 root 0 -20 0 0 0 S 5.6 0.0 1:03.64 z_rd_int
353 root 0 -20 0 0 0 S 5.6 0.0 1:03.64 z_rd_int
354 root 0 -20 0 0 0 S 5.6 0.0 1:04.01 z_rd_int
I wonder how much of that is due to syncoid, particularly because I
often saw mbuffer and pv in there which are not strictly necessary
to do those kind of operations, as far as I understand.
Once that's done, export the pools to disconnect the drive:
Monitoring
ZFS should be monitoring your pools regularly. Normally, the [[!debman
zed]] daemon monitors all ZFS events. It is the thing that will report
when a scrub failed, for example. See this configuration guide.
Scrubs should be regularly scheduled to ensure consistency of the
pool. This can be done in newer zfsutils-linux versions
(bullseye-backports or bookworm) with one of those, depending on the
desired frequency:
When the scrub runs, if it finds anything it will send an event which
will get picked up by the zed daemon which will then send a
notification, see below for an example.
TODO: deploy on curie, if possible (probably not because no RAID)
TODO: this should be in Puppet
Scrub warning example
So what happens when problems are found? Here's an example of how I
dealt with an error I received.
After setting up another server (tubman) with ZFS, I
eventually ended up getting a warning from the ZFS toolchain.
Date: Sun, 09 Oct 2022 00:58:08 -0400
From: root <root@anarc.at>
To: root@anarc.at
Subject: ZFS scrub_finish event for rpool on tubman
ZFS has finished a scrub:
eid: 39536
class: scrub_finish
host: tubman
time: 2022-10-09 00:58:07-0400
pool: rpool
state: ONLINE
status: One or more devices has experienced an unrecoverable error. An
attempt was made to correct the error. Applications are unaffected.
action: Determine if the device needs to be replaced, and clear the errors
using 'zpool clear' or replace the device with 'zpool replace'.
see: https://openzfs.github.io/openzfs-docs/msg/ZFS-8000-9P
scan: scrub repaired 0B in 00:33:57 with 0 errors on Sun Oct 9 00:58:07 2022
config:
NAME STATE READ WRITE CKSUM
rpool ONLINE 0 0 0
mirror-0 ONLINE 0 0 0
sdb4 ONLINE 0 1 0
sdc4 ONLINE 0 0 0
cache
sda3 ONLINE 0 0 0
errors: No known data errors
This, in itself, is a little worrisome. But it helpfully links to this
more detailed documentation (and props up there: the link still
works) which explains this is a "minor" problem (something that could
be included in the report).
In this case, this happened on a server setup on 2021-04-28, but the
disks and server hardware are much older. The server itself
(marcosv1) was built
around 2011, over 10 years ago now. The hard drive in question is:
root@tubman:~# smartctl -i -qnoserial /dev/sdb
smartctl 7.2 2020-12-30 r5155 [x86_64-linux-5.10.0-15-amd64] (local build)
Copyright (C) 2002-20, Bruce Allen, Christian Franke, www.smartmontools.org
=== START OF INFORMATION SECTION ===
Model Family: Seagate BarraCuda 3.5
Device Model: ST4000DM004-2CV104
Firmware Version: 0001
User Capacity: 4,000,787,030,016 bytes [4.00 TB]
Sector Sizes: 512 bytes logical, 4096 bytes physical
Rotation Rate: 5425 rpm
Form Factor: 3.5 inches
Device is: In smartctl database [for details use: -P show]
ATA Version is: ACS-3 T13/2161-D revision 5
SATA Version is: SATA 3.1, 6.0 Gb/s (current: 3.0 Gb/s)
Local Time is: Tue Oct 11 11:02:32 2022 EDT
SMART support is: Available - device has SMART capability.
SMART support is: Enabled
That's over a year of power on, which shouldn't be so bad. It has
written about 10TB of data (21107792664 LBAs * 512 byte/LBA), which
is about two full writes. According to its specification, this
device is supposed to support 55 TB/year of writes, so we're far below
spec. Note that are still far from the "non-recoverable read error per
bits" spec (1 per 10E15), as we've basically read 13E12 bits
(3201579750 LBAs * 512 byte/LBA = 13E12 bits).
It's likely this disk was made in 2018, so it is in its fourth
year.
Interestingly, /dev/sdc is also a Seagate drive, but of a different
series:
root@tubman:~# smartctl -qnoserial -i /dev/sdb
smartctl 7.2 2020-12-30 r5155 [x86_64-linux-5.10.0-15-amd64] (local build)
Copyright (C) 2002-20, Bruce Allen, Christian Franke, www.smartmontools.org
=== START OF INFORMATION SECTION ===
Model Family: Seagate BarraCuda 3.5
Device Model: ST4000DM004-2CV104
Firmware Version: 0001
User Capacity: 4,000,787,030,016 bytes [4.00 TB]
Sector Sizes: 512 bytes logical, 4096 bytes physical
Rotation Rate: 5425 rpm
Form Factor: 3.5 inches
Device is: In smartctl database [for details use: -P show]
ATA Version is: ACS-3 T13/2161-D revision 5
SATA Version is: SATA 3.1, 6.0 Gb/s (current: 3.0 Gb/s)
Local Time is: Tue Oct 11 11:21:35 2022 EDT
SMART support is: Available - device has SMART capability.
SMART support is: Enabled
It has seen much more reads than the other disk which is also interesting:
That's 4 years of Head_Flying_Hours, and over 4 years (4 years and
48 days) of Power_On_Hours. The copyright date on that drive's
specs goes back to 2016, so it's a much older drive.
SMART self-test succeeded.
Remaining issues
TODO: move send/receive backups to offsite host, see also
zfs for alternatives to syncoid/sanoid there
TODO: document this somewhere: bpool and rpool are both pools and
datasets. that's pretty confusing, but also very useful because it
allows for pool-wide recursive snapshots, which are used for the
backup system
fio improvements
I really want to improve my experience with fio. Right now, I'm just
cargo-culting stuff from other folks and I don't really like
it. stressant is a good example of my struggles, in the sense
that it doesn't really work that well for disk tests.
I would love to have just a single .fio job file that lists multiple
jobs to run serially. For example, this file describes the above
workload pretty well:
[global]
# cargo-culting Salter
fallocate=none
ioengine=posixaio
runtime=60
time_based=1
end_fsync=1
stonewall=1
group_reporting=1
# no need to drop caches, done by default
# invalidate=1
# Single 4KiB random read/write process
[randread-4k-4g-1x]
rw=randread
bs=4k
size=4g
numjobs=1
iodepth=1
[randwrite-4k-4g-1x]
rw=randwrite
bs=4k
size=4g
numjobs=1
iodepth=1
# 16 parallel 64KiB random read/write processes:
[randread-64k-256m-16x]
rw=randread
bs=64k
size=256m
numjobs=16
iodepth=16
[randwrite-64k-256m-16x]
rw=randwrite
bs=64k
size=256m
numjobs=16
iodepth=16
# Single 1MiB random read/write process
[randread-1m-16g-1x]
rw=randread
bs=1m
size=16g
numjobs=1
iodepth=1
[randwrite-1m-16g-1x]
rw=randwrite
bs=1m
size=16g
numjobs=1
iodepth=1
... except the jobs are actually started in parallel, even though they
are stonewall'd, as far as I can tell by the reports. I sent a
mail to the fio mailing list for clarification.
It looks like the jobs are started in parallel, but actual
(correctly) run serially. It seems like this might just be a matter of
reporting the right timestamps in the end, although it does feel like
starting all the processes (even if not doing any work yet) could
skew the results.
Hangs during procedure
During the procedure, it happened a few times where any ZFS command
would completely hang. It seems that using an external USB drive to
sync stuff didn't work so well: sometimes it would reconnect under a
different device (from sdc to sdd, for example), and this would
greatly confuse ZFS.
Here, for example, is sdd reappearing out of the blue:
May 19 11:22:53 curie kernel: [ 699.820301] scsi host4: uas
May 19 11:22:53 curie kernel: [ 699.820544] usb 2-1: authorized to connect
May 19 11:22:53 curie kernel: [ 699.922433] scsi 4:0:0:0: Direct-Access ROG ESD-S1C 0 PQ: 0 ANSI: 6
May 19 11:22:53 curie kernel: [ 699.923235] sd 4:0:0:0: Attached scsi generic sg2 type 0
May 19 11:22:53 curie kernel: [ 699.923676] sd 4:0:0:0: [sdd] 1953525168 512-byte logical blocks: (1.00 TB/932 GiB)
May 19 11:22:53 curie kernel: [ 699.923788] sd 4:0:0:0: [sdd] Write Protect is off
May 19 11:22:53 curie kernel: [ 699.923949] sd 4:0:0:0: [sdd] Write cache: enabled, read cache: enabled, doesn't support DPO or FUA
May 19 11:22:53 curie kernel: [ 699.924149] sd 4:0:0:0: [sdd] Optimal transfer size 33553920 bytes
May 19 11:22:53 curie kernel: [ 699.961602] sdd: sdd1 sdd2 sdd3 sdd4
May 19 11:22:53 curie kernel: [ 699.996083] sd 4:0:0:0: [sdd] Attached SCSI disk
Next time I run a ZFS command (say zpool list), the command
completely hangs (D state) and this comes up in the logs:
May 19 11:34:21 curie kernel: [ 1387.914843] zio pool=bpool vdev=/dev/sdc3 error=5 type=2 offset=71344128 size=4096 flags=184880
May 19 11:34:21 curie kernel: [ 1387.914859] zio pool=bpool vdev=/dev/sdc3 error=5 type=2 offset=205565952 size=4096 flags=184880
May 19 11:34:21 curie kernel: [ 1387.914874] zio pool=bpool vdev=/dev/sdc3 error=5 type=2 offset=272789504 size=4096 flags=184880
May 19 11:34:21 curie kernel: [ 1387.914906] zio pool=bpool vdev=/dev/sdc3 error=5 type=1 offset=270336 size=8192 flags=b08c1
May 19 11:34:21 curie kernel: [ 1387.914932] zio pool=bpool vdev=/dev/sdc3 error=5 type=1 offset=1073225728 size=8192 flags=b08c1
May 19 11:34:21 curie kernel: [ 1387.914948] zio pool=bpool vdev=/dev/sdc3 error=5 type=1 offset=1073487872 size=8192 flags=b08c1
May 19 11:34:21 curie kernel: [ 1387.915165] zio pool=bpool vdev=/dev/sdc3 error=5 type=2 offset=272793600 size=4096 flags=184880
May 19 11:34:21 curie kernel: [ 1387.915183] zio pool=bpool vdev=/dev/sdc3 error=5 type=2 offset=339853312 size=4096 flags=184880
May 19 11:34:21 curie kernel: [ 1387.915648] WARNING: Pool 'bpool' has encountered an uncorrectable I/O failure and has been suspended.
May 19 11:34:21 curie kernel: [ 1387.915648]
May 19 11:37:25 curie kernel: [ 1571.558614] task:txg_sync state:D stack: 0 pid: 997 ppid: 2 flags:0x00004000
May 19 11:37:25 curie kernel: [ 1571.558623] Call Trace:
May 19 11:37:25 curie kernel: [ 1571.558640] __schedule+0x282/0x870
May 19 11:37:25 curie kernel: [ 1571.558650] schedule+0x46/0xb0
May 19 11:37:25 curie kernel: [ 1571.558670] schedule_timeout+0x8b/0x140
May 19 11:37:25 curie kernel: [ 1571.558675] ? __next_timer_interrupt+0x110/0x110
May 19 11:37:25 curie kernel: [ 1571.558678] io_schedule_timeout+0x4c/0x80
May 19 11:37:25 curie kernel: [ 1571.558689] __cv_timedwait_common+0x12b/0x160 [spl]
May 19 11:37:25 curie kernel: [ 1571.558694] ? add_wait_queue_exclusive+0x70/0x70
May 19 11:37:25 curie kernel: [ 1571.558702] __cv_timedwait_io+0x15/0x20 [spl]
May 19 11:37:25 curie kernel: [ 1571.558816] zio_wait+0x129/0x2b0 [zfs]
May 19 11:37:25 curie kernel: [ 1571.558929] dsl_pool_sync+0x461/0x4f0 [zfs]
May 19 11:37:25 curie kernel: [ 1571.559032] spa_sync+0x575/0xfa0 [zfs]
May 19 11:37:25 curie kernel: [ 1571.559138] ? spa_txg_history_init_io+0x101/0x110 [zfs]
May 19 11:37:25 curie kernel: [ 1571.559245] txg_sync_thread+0x2e0/0x4a0 [zfs]
May 19 11:37:25 curie kernel: [ 1571.559354] ? txg_fini+0x240/0x240 [zfs]
May 19 11:37:25 curie kernel: [ 1571.559366] thread_generic_wrapper+0x6f/0x80 [spl]
May 19 11:37:25 curie kernel: [ 1571.559376] ? __thread_exit+0x20/0x20 [spl]
May 19 11:37:25 curie kernel: [ 1571.559379] kthread+0x11b/0x140
May 19 11:37:25 curie kernel: [ 1571.559382] ? __kthread_bind_mask+0x60/0x60
May 19 11:37:25 curie kernel: [ 1571.559386] ret_from_fork+0x22/0x30
May 19 11:37:25 curie kernel: [ 1571.559401] task:zed state:D stack: 0 pid: 1564 ppid: 1 flags:0x00000000
May 19 11:37:25 curie kernel: [ 1571.559404] Call Trace:
May 19 11:37:25 curie kernel: [ 1571.559409] __schedule+0x282/0x870
May 19 11:37:25 curie kernel: [ 1571.559412] ? __kmalloc_node+0x141/0x2b0
May 19 11:37:25 curie kernel: [ 1571.559417] schedule+0x46/0xb0
May 19 11:37:25 curie kernel: [ 1571.559420] schedule_preempt_disabled+0xa/0x10
May 19 11:37:25 curie kernel: [ 1571.559424] __mutex_lock.constprop.0+0x133/0x460
May 19 11:37:25 curie kernel: [ 1571.559435] ? nvlist_xalloc.part.0+0x68/0xc0 [znvpair]
May 19 11:37:25 curie kernel: [ 1571.559537] spa_all_configs+0x41/0x120 [zfs]
May 19 11:37:25 curie kernel: [ 1571.559644] zfs_ioc_pool_configs+0x17/0x70 [zfs]
May 19 11:37:25 curie kernel: [ 1571.559752] zfsdev_ioctl_common+0x697/0x870 [zfs]
May 19 11:37:25 curie kernel: [ 1571.559758] ? _copy_from_user+0x28/0x60
May 19 11:37:25 curie kernel: [ 1571.559860] zfsdev_ioctl+0x53/0xe0 [zfs]
May 19 11:37:25 curie kernel: [ 1571.559866] __x64_sys_ioctl+0x83/0xb0
May 19 11:37:25 curie kernel: [ 1571.559869] do_syscall_64+0x33/0x80
May 19 11:37:25 curie kernel: [ 1571.559873] entry_SYSCALL_64_after_hwframe+0x44/0xa9
May 19 11:37:25 curie kernel: [ 1571.559876] RIP: 0033:0x7fcf0ef32cc7
May 19 11:37:25 curie kernel: [ 1571.559878] RSP: 002b:00007fcf0e181618 EFLAGS: 00000246 ORIG_RAX: 0000000000000010
May 19 11:37:25 curie kernel: [ 1571.559881] RAX: ffffffffffffffda RBX: 000055b212f972a0 RCX: 00007fcf0ef32cc7
May 19 11:37:25 curie kernel: [ 1571.559883] RDX: 00007fcf0e181640 RSI: 0000000000005a04 RDI: 000000000000000b
May 19 11:37:25 curie kernel: [ 1571.559885] RBP: 00007fcf0e184c30 R08: 00007fcf08016810 R09: 00007fcf08000080
May 19 11:37:25 curie kernel: [ 1571.559886] R10: 0000000000080000 R11: 0000000000000246 R12: 000055b212f972a0
May 19 11:37:25 curie kernel: [ 1571.559888] R13: 0000000000000000 R14: 00007fcf0e181640 R15: 0000000000000000
May 19 11:37:25 curie kernel: [ 1571.559980] task:zpool state:D stack: 0 pid:11815 ppid: 3816 flags:0x00004000
May 19 11:37:25 curie kernel: [ 1571.559983] Call Trace:
May 19 11:37:25 curie kernel: [ 1571.559988] __schedule+0x282/0x870
May 19 11:37:25 curie kernel: [ 1571.559992] schedule+0x46/0xb0
May 19 11:37:25 curie kernel: [ 1571.559995] io_schedule+0x42/0x70
May 19 11:37:25 curie kernel: [ 1571.560004] cv_wait_common+0xac/0x130 [spl]
May 19 11:37:25 curie kernel: [ 1571.560008] ? add_wait_queue_exclusive+0x70/0x70
May 19 11:37:25 curie kernel: [ 1571.560118] txg_wait_synced_impl+0xc9/0x110 [zfs]
May 19 11:37:25 curie kernel: [ 1571.560223] txg_wait_synced+0xc/0x40 [zfs]
May 19 11:37:25 curie kernel: [ 1571.560325] spa_export_common+0x4cd/0x590 [zfs]
May 19 11:37:25 curie kernel: [ 1571.560430] ? zfs_log_history+0x9c/0xf0 [zfs]
May 19 11:37:25 curie kernel: [ 1571.560537] zfsdev_ioctl_common+0x697/0x870 [zfs]
May 19 11:37:25 curie kernel: [ 1571.560543] ? _copy_from_user+0x28/0x60
May 19 11:37:25 curie kernel: [ 1571.560644] zfsdev_ioctl+0x53/0xe0 [zfs]
May 19 11:37:25 curie kernel: [ 1571.560649] __x64_sys_ioctl+0x83/0xb0
May 19 11:37:25 curie kernel: [ 1571.560653] do_syscall_64+0x33/0x80
May 19 11:37:25 curie kernel: [ 1571.560656] entry_SYSCALL_64_after_hwframe+0x44/0xa9
May 19 11:37:25 curie kernel: [ 1571.560659] RIP: 0033:0x7fdc23be2cc7
May 19 11:37:25 curie kernel: [ 1571.560661] RSP: 002b:00007ffc8c792478 EFLAGS: 00000246 ORIG_RAX: 0000000000000010
May 19 11:37:25 curie kernel: [ 1571.560664] RAX: ffffffffffffffda RBX: 000055942ca49e20 RCX: 00007fdc23be2cc7
May 19 11:37:25 curie kernel: [ 1571.560666] RDX: 00007ffc8c792490 RSI: 0000000000005a03 RDI: 0000000000000003
May 19 11:37:25 curie kernel: [ 1571.560667] RBP: 00007ffc8c795e80 R08: 00000000ffffffff R09: 00007ffc8c792310
May 19 11:37:25 curie kernel: [ 1571.560669] R10: 000055942ca49e30 R11: 0000000000000246 R12: 00007ffc8c792490
May 19 11:37:25 curie kernel: [ 1571.560671] R13: 000055942ca49e30 R14: 000055942aed2c20 R15: 00007ffc8c795a40
Here's another example, where you see the USB controller bleeping out
and back into existence:
mai 19 11:38:39 curie kernel: usb 2-1: USB disconnect, device number 2
mai 19 11:38:39 curie kernel: sd 4:0:0:0: [sdd] Synchronizing SCSI cache
mai 19 11:38:39 curie kernel: sd 4:0:0:0: [sdd] Synchronize Cache(10) failed: Result: hostbyte=DID_ERROR driverbyte=DRIVER_OK
mai 19 11:39:25 curie kernel: INFO: task zed:1564 blocked for more than 241 seconds.
mai 19 11:39:25 curie kernel: Tainted: P IOE 5.10.0-14-amd64 #1 Debian 5.10.113-1
mai 19 11:39:25 curie kernel: "echo 0 > /proc/sys/kernel/hung_task_timeout_secs" disables this message.
mai 19 11:39:25 curie kernel: task:zed state:D stack: 0 pid: 1564 ppid: 1 flags:0x00000000
mai 19 11:39:25 curie kernel: Call Trace:
mai 19 11:39:25 curie kernel: __schedule+0x282/0x870
mai 19 11:39:25 curie kernel: ? __kmalloc_node+0x141/0x2b0
mai 19 11:39:25 curie kernel: schedule+0x46/0xb0
mai 19 11:39:25 curie kernel: schedule_preempt_disabled+0xa/0x10
mai 19 11:39:25 curie kernel: __mutex_lock.constprop.0+0x133/0x460
mai 19 11:39:25 curie kernel: ? nvlist_xalloc.part.0+0x68/0xc0 [znvpair]
mai 19 11:39:25 curie kernel: spa_all_configs+0x41/0x120 [zfs]
mai 19 11:39:25 curie kernel: zfs_ioc_pool_configs+0x17/0x70 [zfs]
mai 19 11:39:25 curie kernel: zfsdev_ioctl_common+0x697/0x870 [zfs]
mai 19 11:39:25 curie kernel: ? _copy_from_user+0x28/0x60
mai 19 11:39:25 curie kernel: zfsdev_ioctl+0x53/0xe0 [zfs]
mai 19 11:39:25 curie kernel: __x64_sys_ioctl+0x83/0xb0
mai 19 11:39:25 curie kernel: do_syscall_64+0x33/0x80
mai 19 11:39:25 curie kernel: entry_SYSCALL_64_after_hwframe+0x44/0xa9
mai 19 11:39:25 curie kernel: RIP: 0033:0x7fcf0ef32cc7
mai 19 11:39:25 curie kernel: RSP: 002b:00007fcf0e181618 EFLAGS: 00000246 ORIG_RAX: 0000000000000010
mai 19 11:39:25 curie kernel: RAX: ffffffffffffffda RBX: 000055b212f972a0 RCX: 00007fcf0ef32cc7
mai 19 11:39:25 curie kernel: RDX: 00007fcf0e181640 RSI: 0000000000005a04 RDI: 000000000000000b
mai 19 11:39:25 curie kernel: RBP: 00007fcf0e184c30 R08: 00007fcf08016810 R09: 00007fcf08000080
mai 19 11:39:25 curie kernel: R10: 0000000000080000 R11: 0000000000000246 R12: 000055b212f972a0
mai 19 11:39:25 curie kernel: R13: 0000000000000000 R14: 00007fcf0e181640 R15: 0000000000000000
mai 19 11:39:25 curie kernel: INFO: task zpool:11815 blocked for more than 241 seconds.
mai 19 11:39:25 curie kernel: Tainted: P IOE 5.10.0-14-amd64 #1 Debian 5.10.113-1
mai 19 11:39:25 curie kernel: "echo 0 > /proc/sys/kernel/hung_task_timeout_secs" disables this message.
mai 19 11:39:25 curie kernel: task:zpool state:D stack: 0 pid:11815 ppid: 2621 flags:0x00004004
mai 19 11:39:25 curie kernel: Call Trace:
mai 19 11:39:25 curie kernel: __schedule+0x282/0x870
mai 19 11:39:25 curie kernel: schedule+0x46/0xb0
mai 19 11:39:25 curie kernel: io_schedule+0x42/0x70
mai 19 11:39:25 curie kernel: cv_wait_common+0xac/0x130 [spl]
mai 19 11:39:25 curie kernel: ? add_wait_queue_exclusive+0x70/0x70
mai 19 11:39:25 curie kernel: txg_wait_synced_impl+0xc9/0x110 [zfs]
mai 19 11:39:25 curie kernel: txg_wait_synced+0xc/0x40 [zfs]
mai 19 11:39:25 curie kernel: spa_export_common+0x4cd/0x590 [zfs]
mai 19 11:39:25 curie kernel: ? zfs_log_history+0x9c/0xf0 [zfs]
mai 19 11:39:25 curie kernel: zfsdev_ioctl_common+0x697/0x870 [zfs]
mai 19 11:39:25 curie kernel: ? _copy_from_user+0x28/0x60
mai 19 11:39:25 curie kernel: zfsdev_ioctl+0x53/0xe0 [zfs]
mai 19 11:39:25 curie kernel: __x64_sys_ioctl+0x83/0xb0
mai 19 11:39:25 curie kernel: do_syscall_64+0x33/0x80
mai 19 11:39:25 curie kernel: entry_SYSCALL_64_after_hwframe+0x44/0xa9
mai 19 11:39:25 curie kernel: RIP: 0033:0x7fdc23be2cc7
mai 19 11:39:25 curie kernel: RSP: 002b:00007ffc8c792478 EFLAGS: 00000246 ORIG_RAX: 0000000000000010
mai 19 11:39:25 curie kernel: RAX: ffffffffffffffda RBX: 000055942ca49e20 RCX: 00007fdc23be2cc7
mai 19 11:39:25 curie kernel: RDX: 00007ffc8c792490 RSI: 0000000000005a03 RDI: 0000000000000003
mai 19 11:39:25 curie kernel: RBP: 00007ffc8c795e80 R08: 00000000ffffffff R09: 00007ffc8c792310
mai 19 11:39:25 curie kernel: R10: 000055942ca49e30 R11: 0000000000000246 R12: 00007ffc8c792490
mai 19 11:39:25 curie kernel: R13: 000055942ca49e30 R14: 000055942aed2c20 R15: 00007ffc8c795a40
I understand those are rather extreme conditions: I would fully expect
the pool to stop working if the underlying drives disappear. What
doesn't seem acceptable is that a command would completely hang like
this.
References
See the zfs documentation for more information about ZFS,
and tubman for another installation and migration procedure.
If you ve done anything in the Kubernetes space in recent years, you ve most likely come across the words Service Mesh . It s backed by a set of mature technologies that provides cross-cutting networking, security, infrastructure capabilities to be used by workloads running in Kubernetes in a manner that is transparent to the actual workload. This abstraction enables application developers to not worry about building in otherwise sophisticated capabilities for networking, routing, circuit-breaking and security, and simply rely on the services offered by the service mesh.In this post, I ll be covering Linkerd, which is an alternative to Istio. It has gone through a significant re-write when it transitioned from the JVM to a Go-based Control Plane and a Rust-based Data Plane a few years back and is now a part of the CNCF and is backed by Buoyant. It has proven itself widely for use in production workloads and has a healthy community and release cadence.It achieves this with a side-car container that communicates with a Linkerd control plane that allows central management of policy, telemetry, mutual TLS, traffic routing, shaping, retries, load balancing, circuit-breaking and other cross-cutting concerns before the traffic hits the container. This has made the task of implementing the application services much simpler as it is managed by container orchestrator and service mesh. I covered Istio in a prior post a few years back, and much of the content is still applicable for this post, if you d like to have a look.Here are the broad architectural components of Linkerd:The components are separated into the control plane and the data plane.The control plane components live in its own namespace and consists of a controller that the Linkerd CLI interacts with via the Kubernetes API. The destination service is used for service discovery, TLS identity, policy on access control for inter-service communication and service profile information on routing, retries, timeouts. The identity service acts as the Certificate Authority which responds to Certificate Signing Requests (CSRs) from proxies for initialization and for service-to-service encrypted traffic. The proxy injector is an admission webhook that injects the Linkerd proxy side car and the init container automatically into a pod when the linkerd.io/inject: enabled is available on the namespace or workload.On the data plane side are two components. First, the init container, which is responsible for automatically forwarding incoming and outgoing traffic through the Linkerd proxy via iptables rules. Second, the Linkerd proxy, which is a lightweight micro-proxy written in Rust, is the data plane itself.I will be walking you through the setup of Linkerd (2.12.2 at the time of writing) on a Kubernetes cluster.Let s see what s running on the cluster currently. This assumes you have a cluster running and kubectl is installed and available on the PATH.
On most systems, this should be sufficient to setup the CLI. You may need to restart your terminal to load the updated paths. If you have a non-standard configuration and linkerd is not found after the installation, add the following to your PATH to be able to find the cli:
export PATH=$PATH:~/.linkerd2/bin/
At this point, checking the version would give you the following:
$ linkerd version Client version: stable-2.12.2 Server version: unavailable
Setting up Linkerd Control PlaneBefore installing Linkerd on the cluster, run the following step to check the cluster for pre-requisites:
kubernetes-api -------------- can initialize the client can query the Kubernetes API
kubernetes-version ------------------ is running the minimum Kubernetes API version is running the minimum kubectl version
pre-kubernetes-setup -------------------- control plane namespace does not already exist can create non-namespaced resources can create ServiceAccounts can create Services can create Deployments can create CronJobs can create ConfigMaps can create Secrets can read Secrets can read extension-apiserver-authentication configmap no clock skew detected
linkerd-version --------------- can determine the latest version cli is up-to-date
Status check results are
All the pre-requisites appear to be good right now, and so installation can proceed.The first step of the installation is to setup the Custom Resource Definitions (CRDs) that Linkerd requires. The linkerd cli only prints the resource YAMLs to standard output and does not create them directly in Kubernetes, so you would need to pipe the output to kubectl apply to create the resources in the cluster that you re working with.
$ linkerd install --crds kubectl apply -f - Rendering Linkerd CRDs... Next, run linkerd install kubectl apply -f - to install the control plane.
customresourcedefinition.apiextensions.k8s.io/authorizationpolicies.policy.linkerd.io created customresourcedefinition.apiextensions.k8s.io/httproutes.policy.linkerd.io created customresourcedefinition.apiextensions.k8s.io/meshtlsauthentications.policy.linkerd.io created customresourcedefinition.apiextensions.k8s.io/networkauthentications.policy.linkerd.io created customresourcedefinition.apiextensions.k8s.io/serverauthorizations.policy.linkerd.io created customresourcedefinition.apiextensions.k8s.io/servers.policy.linkerd.io created customresourcedefinition.apiextensions.k8s.io/serviceprofiles.linkerd.io created
Next, install the Linkerd control plane components in the same manner, this time without the crds switch:
$ linkerd install kubectl apply -f - namespace/linkerd created clusterrole.rbac.authorization.k8s.io/linkerd-linkerd-identity created clusterrolebinding.rbac.authorization.k8s.io/linkerd-linkerd-identity created serviceaccount/linkerd-identity created clusterrole.rbac.authorization.k8s.io/linkerd-linkerd-destination created clusterrolebinding.rbac.authorization.k8s.io/linkerd-linkerd-destination created serviceaccount/linkerd-destination created secret/linkerd-sp-validator-k8s-tls created validatingwebhookconfiguration.admissionregistration.k8s.io/linkerd-sp-validator-webhook-config created secret/linkerd-policy-validator-k8s-tls created validatingwebhookconfiguration.admissionregistration.k8s.io/linkerd-policy-validator-webhook-config created clusterrole.rbac.authorization.k8s.io/linkerd-policy created clusterrolebinding.rbac.authorization.k8s.io/linkerd-destination-policy created role.rbac.authorization.k8s.io/linkerd-heartbeat created rolebinding.rbac.authorization.k8s.io/linkerd-heartbeat created clusterrole.rbac.authorization.k8s.io/linkerd-heartbeat created clusterrolebinding.rbac.authorization.k8s.io/linkerd-heartbeat created serviceaccount/linkerd-heartbeat created clusterrole.rbac.authorization.k8s.io/linkerd-linkerd-proxy-injector created clusterrolebinding.rbac.authorization.k8s.io/linkerd-linkerd-proxy-injector created serviceaccount/linkerd-proxy-injector created secret/linkerd-proxy-injector-k8s-tls created mutatingwebhookconfiguration.admissionregistration.k8s.io/linkerd-proxy-injector-webhook-config created configmap/linkerd-config created secret/linkerd-identity-issuer created configmap/linkerd-identity-trust-roots created service/linkerd-identity created service/linkerd-identity-headless created deployment.apps/linkerd-identity created service/linkerd-dst created service/linkerd-dst-headless created service/linkerd-sp-validator created service/linkerd-policy created service/linkerd-policy-validator created deployment.apps/linkerd-destination created cronjob.batch/linkerd-heartbeat created deployment.apps/linkerd-proxy-injector created service/linkerd-proxy-injector created secret/linkerd-config-overrides created
Kubernetes will start spinning up the data plane components and you should see the following when you list the pods:
kubernetes-api -------------- can initialize the client can query the Kubernetes API
kubernetes-version ------------------ is running the minimum Kubernetes API version is running the minimum kubectl version
linkerd-existence ----------------- 'linkerd-config' config map exists heartbeat ServiceAccount exist control plane replica sets are ready no unschedulable pods control plane pods are ready cluster networks contains all pods cluster networks contains all services
linkerd-config -------------- control plane Namespace exists control plane ClusterRoles exist control plane ClusterRoleBindings exist control plane ServiceAccounts exist control plane CustomResourceDefinitions exist control plane MutatingWebhookConfigurations exist control plane ValidatingWebhookConfigurations exist proxy-init container runs as root user if docker container runtime is used
linkerd-identity ---------------- certificate config is valid trust anchors are using supported crypto algorithm trust anchors are within their validity period trust anchors are valid for at least 60 days issuer cert is using supported crypto algorithm issuer cert is within its validity period issuer cert is valid for at least 60 days issuer cert is issued by the trust anchor
linkerd-webhooks-and-apisvc-tls ------------------------------- proxy-injector webhook has valid cert proxy-injector cert is valid for at least 60 days sp-validator webhook has valid cert sp-validator cert is valid for at least 60 days policy-validator webhook has valid cert policy-validator cert is valid for at least 60 days
linkerd-version --------------- can determine the latest version cli is up-to-date
control-plane-version --------------------- can retrieve the control plane version control plane is up-to-date control plane and cli versions match
linkerd-control-plane-proxy --------------------------- control plane proxies are healthy control plane proxies are up-to-date control plane proxies and cli versions match
Status check results are
Everything looks good.Setting up the Viz ExtensionAt this point, the required components for the service mesh are setup, but let s also install the viz extension, which provides a good visualization capabilities that will come in handy subsequently. Once again, linkerd uses the same pattern for installing the extension.
$ linkerd viz install kubectl apply -f - namespace/linkerd-viz created clusterrole.rbac.authorization.k8s.io/linkerd-linkerd-viz-metrics-api created clusterrolebinding.rbac.authorization.k8s.io/linkerd-linkerd-viz-metrics-api created serviceaccount/metrics-api created clusterrole.rbac.authorization.k8s.io/linkerd-linkerd-viz-prometheus created clusterrolebinding.rbac.authorization.k8s.io/linkerd-linkerd-viz-prometheus created serviceaccount/prometheus created clusterrole.rbac.authorization.k8s.io/linkerd-linkerd-viz-tap created clusterrole.rbac.authorization.k8s.io/linkerd-linkerd-viz-tap-admin created clusterrolebinding.rbac.authorization.k8s.io/linkerd-linkerd-viz-tap created clusterrolebinding.rbac.authorization.k8s.io/linkerd-linkerd-viz-tap-auth-delegator created serviceaccount/tap created rolebinding.rbac.authorization.k8s.io/linkerd-linkerd-viz-tap-auth-reader created secret/tap-k8s-tls created apiservice.apiregistration.k8s.io/v1alpha1.tap.linkerd.io created role.rbac.authorization.k8s.io/web created rolebinding.rbac.authorization.k8s.io/web created clusterrole.rbac.authorization.k8s.io/linkerd-linkerd-viz-web-check created clusterrolebinding.rbac.authorization.k8s.io/linkerd-linkerd-viz-web-check created clusterrolebinding.rbac.authorization.k8s.io/linkerd-linkerd-viz-web-admin created clusterrole.rbac.authorization.k8s.io/linkerd-linkerd-viz-web-api created clusterrolebinding.rbac.authorization.k8s.io/linkerd-linkerd-viz-web-api created serviceaccount/web created server.policy.linkerd.io/admin created authorizationpolicy.policy.linkerd.io/admin created networkauthentication.policy.linkerd.io/kubelet created server.policy.linkerd.io/proxy-admin created authorizationpolicy.policy.linkerd.io/proxy-admin created service/metrics-api created deployment.apps/metrics-api created server.policy.linkerd.io/metrics-api created authorizationpolicy.policy.linkerd.io/metrics-api created meshtlsauthentication.policy.linkerd.io/metrics-api-web created configmap/prometheus-config created service/prometheus created deployment.apps/prometheus created service/tap created deployment.apps/tap created server.policy.linkerd.io/tap-api created authorizationpolicy.policy.linkerd.io/tap created clusterrole.rbac.authorization.k8s.io/linkerd-tap-injector created clusterrolebinding.rbac.authorization.k8s.io/linkerd-tap-injector created serviceaccount/tap-injector created secret/tap-injector-k8s-tls created mutatingwebhookconfiguration.admissionregistration.k8s.io/linkerd-tap-injector-webhook-config created service/tap-injector created deployment.apps/tap-injector created server.policy.linkerd.io/tap-injector-webhook created authorizationpolicy.policy.linkerd.io/tap-injector created networkauthentication.policy.linkerd.io/kube-api-server created service/web created deployment.apps/web created serviceprofile.linkerd.io/metrics-api.linkerd-viz.svc.cluster.local created serviceprofile.linkerd.io/prometheus.linkerd-viz.svc.cluster.local created
A few seconds later, you should see the following in your pod list:
The viz components live in the linkerd-viz namespace.You can now checkout the viz dashboard:
$ linkerd viz dashboard Linkerd dashboard available at: http://localhost:50750 Grafana dashboard available at: http://localhost:50750/grafana Opening Linkerd dashboard in the default browser Opening in existing browser session.
The Meshed column indicates the workload that is currently integrated with the Linkerd control plane. As you can see, there are no application deployments right now that are running.Injecting the Linkerd Data Plane componentsThere are two ways to integrate Linkerd to the application containers:1 by manually injecting the Linkerd data plane components 2 by instructing Kubernetes to automatically inject the data plane componentsInject Linkerd data plane manuallyLet s try the first option. Below is a simple nginx-app that I will deploy into the cluster:
Back in the viz dashboard, I do see the workload deployed, but it isn t currently communicating with the Linkerd control plane, and so doesn t show any metrics, and the Meshed count is 0:Looking at the Pod s deployment YAML, I can see that it only includes the nginx container:
Let s directly inject the linkerd data plane into this running container. We do this by retrieving the YAML of the deployment, piping it to linkerd cli to inject the necessary components and then piping to kubectl apply the changed resources.
Back in the viz dashboard, the workload now is integrated into Linkerd control plane.Looking at the updated Pod definition, we see a number of changes that the linkerd has injected that allows it to integrate with the control plane. Let s have a look:
At this point, the necessary components are setup for you to explore Linkerd further. You can also try out the jaeger and multicluster extensions, similar to the process of installing and using the viz extension and try out their capabilities.Inject Linkerd data plane automaticallyIn this approach, we shall we how to instruct Kubernetes to automatically inject the Linkerd data plane to workloads at deployment time.We can achieve this by adding the linkerd.io/inject annotation to the deployment descriptor which causes the proxy injector admission hook to execute and inject linkerd data plane components automatically at the time of deployment.
This annotation can also be specified at the namespace level to affect all the workloads within the namespace. Note that any resources created before the annotation was added to the namespace will require a rollout restart to trigger the injection of the Linkerd components.Uninstalling LinkerdNow that we have walked through the installation and setup process of Linkerd, let s also cover how to remove it from the infrastructure and go back to the state prior to its installation.The first step would be to remove extensions, such as viz.
I m trying to replace my old OpenPGP key with a new one. The old key wasn t compromised or lost or anything
bad. Is still valid, but I plan to get rid of it soon. It was created in 2013.
The new key id fingerprint is: AA66280D4EF0BFCC6BFC2104DA5ECB231C8F04C4
I plan to use the new key for things like encrypted emails, uploads to the Debian archive, and more. Also,
the new key includes an identity with a newer personal email address I plan to use soon: arturo.bg@arturo.bg
The new key has been uploaded to some public keyservers.
If you would like to sign the new key, please follow the steps in the Debian wiki.
If you are curious about what that long code block contains, check this https://cirw.in/gpg-decoder/
For the record, the old key fingerprint is: DD9861AB23DC3333892E07A968E713981D1515F8
Cheers!
Our local Debian user group gathered on Sunday October 30th to chat, work on
Debian and do other, non-Debian related hacking :) This time around, we met at
EfficiOS's1 offices. As you can see from the following
picture, it's a great place and the view they have is pretty awesome. Many
thanks for hosting us!
This was our 4th meeting this year and once again, attendance was great: 10
people showed up to work on various things.
Following our bi-monthly schedule, our next meeting should be in December, but
I'm not sure it'll happen. December can be a busy month here and I will have to
poke our mailing list to see if people have the spoons for an event.
This time around, I was able to get a rough log of the Debian work people did:
pollo:
The purpose of this post is to demonstrate a first approach to the analysis of multiwavelength kinetic data, like those obtained using stopped-flow data. To practice, we will use data that were acquired during the stopped flow practicals of the MetBio summer school from the FrenchBIC. During the practicals, the student monitored the reaction of myoglobin (in its Fe(III) state) with azide, which yields a fast and strong change in the absorbance spectrum of the protein, which was monitored using a diode array. The data is publicly available on zenodo.
Aims of this tutorial
The purpose of this tutorial is to teach you to use the free softwareQSoas to run a simple, multiwavelength exponential fit on the data, and to look at the results. This is not a kinetics lecture, so that it will not go in depth about the use of the exponential fit and its meaning.
Getting started: loading the file
First, make sure you have a working version of QSoas, you can download them (for free) there. Then download the data files from zenodo. We will work only on the data file Azide-1.25mm_001.dat, but of course, the purpose of this tutorial is to enable you to work on all of them. The data files contain the time evolution of the absorbance for all wavelengths, in a matrix format, in which each row correpond to a time point and each column to a wavelength.
Start QSoas, and launch the command:
QSoas> load /comments='"'
Then, choose the Azide-1.25mm_001.dat data file. This should bring up a horizontal red line at the bottom of the data display, with X values between about 0 and 2.5. If you zoom on the red line with the mouse wheel, you'll realize it is data. The /comments='"' part is very important since it allows the extraction of the wavelength from the data. We will look at what it means another day. At this stage, you can look at the loaded data using the command:
QSoas> edit
You should have a window looking like this:
The rows each correspond to a data point displayed on the window below. The first column correspond to the X values, the second the Y values, and all the other ones to extra Y columns (they are not displayed by default). What is especially interesting is the first row, which contains a nan as the X value and what is obviously the wavelength for all the Y values. To tell that QSoas should take this line as the wavelength (which will be the perpendicular coordinate, the coordinate of the other direction of the matrix), first close the edit window and run:
QSoas> set-perp /from-row=0
Splitting and fitting
Now, we have a single dataset containing a lot of Y columns. We want to fit all of them simultaneously with a (mono) exponential fit. For that, we first need to split the big matrix into a series of X,Y datasets (because fitting only works on the first Y). This is possible by running:
QSoas> expand /style=red-to-blue /flags=kinetics
Your screen should now look like this:
You're looking at the kinetics at all wavelengths at the same time (this may take some time to display on your computer, it is after all a rather large number of data points). The /style=red-to-blue is not strictly necessary, but it gives the red to blue color gradient which makes things easier to look at (and cooler !). The /flags=kinetics is there to attach a label (a flag) to the newly created datasets so we can easily manipulate all of them at the same time. Then it's time to fit, with the following command:
QSoas> mfit-exponential-decay flagged:kinetics
This should bring up a new window. After resizing it, you should have something that looks like this:
The bottom of the fit window is taken by the parameters, each with two checkboxes on the right to set them fixed (i.e. not determined by the fitting mechanism) and/or global (i.e. with a single value for all the datasets, here all the wavelengths). The top shows the current dataset along with the corresponding fit (in green), and, below, the residuals. You can change the dataset by clicking on the horizontal arrows or using Ctrl+PgUp or Ctrl+PgDown (keep holding it to scan fast). See the Z = 728.15 showing that QSoas has recognized that the currently displayed dataset corresponds to the wavelength 728.15. The equation fitted to the data is: $$y(x) = A_\infty + A_1 \times \exp -(x - x_0)/\tau_1$$
In this case, while the \(A_1\) and \(A_\infty\) parameters clearly depend on the wavelength, the time constant of evolution should be independent of wavelength (the process happens at a certain rate regardless of the wavelength we're analyzing), so that the \(\tau_1\) parameter should be common for all the datasets/wavelengths. Just click on the global checkbox at the right of the tau_1 parameter, make sure it is checked, and hit the Fit button...
The fit should not take long (less than a minute), and then you end up with the results of the fits: all the parameters. The best way to look at the non global parameters like \(A_1\) and \(A_\infty\) is to use the Show Parameters item from the Parameters menu. Using it and clicking on A_inf too should give you a display like this one:
The A_inf parameter corresponds to the spectum at infinite time (of azide-bound heme), while the A_1 parameter corresponds to the difference spectrum between the initial (azide-free) and final (azide-bound) states.
Now, the fit is finished, you can save the parameters if you want to reload them in a later fit by using the Parameters/Save menu item or export them in a form more suitable for plotting using Parameters/Export (although QSoas can also display and the parameters saved using Save). This concludes this first approach to fitting the data. What you can do is
look at the depence of the tau_1 parameter as a function of the azide concentration;
try fitting more than one exponential, using for instance:
How to read the code above
All the lines starting by QSoas> in the code areas above are meant to be typed into the QSoas command line (at the bottom of the window), and started by pressing enter at the end. You must remove the QSoas> bit. The other lines (when applicable) show you the response of QSoas, in the terminal just above the command-line. You may want to play with the QSoas tutorial to learn more about how to interact with QSoas.
About QSoas
QSoas is a powerful open source data analysis program that focuses on flexibility and powerful fitting capacities. It is released under the GNU General Public License. It is described in Fourmond, Anal. Chem., 2016, 88 (10), pp 5050 5052. Current version is 3.1. You can freely (and at no cost) download its source code or precompiled versions for MacOS and Windows there. Alternatively, you can clone from the GitHub repository.
Contact: find my email address there, or contact me on LinkedIn.
Fast laptops are expensive, cheap laptops are slow. But even a fast laptop is slower than a decent workstation, and if your developers want a local build environment they're probably going to want a decent workstation. They'll want a fast (and expensive) laptop as well, though, because they're not going to carry their workstation home with them and obviously you expect them to be able to work from home. And in two or three years they'll probably want a new laptop and a new workstation, and that's even more money. Not to mention the risks associated with them doing development work on their laptop and then drunkenly leaving it in a bar or having it stolen or the contents being copied off it while they're passing through immigration at an airport. Surely there's a better way?
This is the thinking that leads to "Let's give developers a Chromebook and a VM running in the cloud". And it's an appealing option! You spend far less on the laptop, and the VM is probably cheaper than the workstation - you can shut it down when it's idle, you can upgrade it to have more CPUs and RAM as necessary, and you get to impose all sorts of additional neat security policies because you have full control over the network. You can run a full desktop environment on the VM, stream it to a cheap laptop, and get the fast workstation experience on something that weighs about a kilogram. Your developers get the benefit of a fast machine wherever they are, and everyone's happy.
But having worked at more than one company that's tried this approach, my experience is that very few people end up happy. I'm going to give a few reasons here, but I can't guarantee that they cover everything - and, to be clear, many (possibly most) of the reasons I'm going to describe aren't impossible to fix, they're simply not priorities. I'm also going to restrict this discussion to the case of "We run a full graphical environment on the VM, and stream that to the laptop" - an approach that only offers SSH access is much more manageable, but also significantly more restricted in certain ways. With those details mentioned, let's begin.
The first thing to note is that the overall experience is heavily tied to the protocol you use for the remote display. Chrome Remote Desktop is extremely appealing from a simplicity perspective, but is also lacking some extremely key features (eg, letting you use multiple displays on the local system), so from a developer perspective it's suboptimal. If you read the rest of this post and want to try this anyway, spend some time working with your users to find out what their requirements are and figure out which technology best suits them.
Second, let's talk about GPUs. Trying to run a modern desktop environment without any GPU acceleration is going to be a miserable experience. Sure, throwing enough CPU at the problem will get you past the worst of this, but you're still going to end up with users who need to do 3D visualisation, or who are doing VR development, or who expect WebGL to work without burning up every single one of the CPU cores you so graciously allocated to their VM. Cloud providers will happily give you GPU instances, but that's going to cost more and you're going to need to re-run your numbers to verify that this is still a financial win. "But most of my users don't need that!" you might say, and we'll get to that later on.
Next! Video quality! This seems like a trivial point, but if you're giving your users a VM as their primary interface, then they're going to do things like try to use Youtube inside it because there's a conference presentation that's relevant to their interests. The obvious solution here is "Do your video streaming in a browser on the local system, not on the VM" but from personal experience that's a super awkward pain point! If I click on a link inside the VM it's going to open a browser there, and now I have a browser in the VM and a local browser and which of them contains the tab I'm looking for WHO CAN SAY. So your users are going to watch stuff inside their VM, and re-compressing decompressed video is going to look like shit unless you're throwing a huge amount of bandwidth at the problem. And this is ignoring the additional irritation of your browser being unreadable while you're rapidly scrolling through pages, or terminal output from build processes being a muddy blur of artifacts, or the corner case of "I work for Youtube and I need to be able to examine 4K streams to determine whether changes have resulted in a degraded experience" which is a very real job and one that becomes impossible when you pass their lovingly crafted optimisations through whatever codec your remote desktop protocol has decided to pick based on some random guesses about the local network, and look everyone is going to have a bad time.
The browser experience. As mentioned before, you'll have local browsers and remote browsers. Do they have the same security policy? Who knows! Are all the third party services you depend on going to be ok with the same user being logged in from two different IPs simultaneously because they lost track of which browser they had an open session in? Who knows! Are your users going to become frustrated? Who knows oh wait no I know the answer to this one, it's "yes".
Accessibility! More of your users than you expect rely on various accessibility interfaces, be those mechanisms for increasing contrast, screen magnifiers, text-to-speech, speech-to-text, alternative input mechanisms and so on. And you probably don't know this, but most of these mechanisms involve having accessibility software be able to introspect the UI of applications in order to provide appropriate input or expose available options and the like. So, I'm running a local text-to-speech agent. How does it know what's happening in the remote VM? It doesn't because it's just getting an a/v stream, so you need to run another accessibility stack inside the remote VM and the two of them are unaware of each others existence and this works just as badly as you'd think. Alternative input mechanism? Good fucking luck with that, you're at best going to fall back to "Send synthesized keyboard inputs" and that is nowhere near as good as "Set the contents of this text box to this unicode string" and yeah I used to work on accessibility software maybe you can tell. And how is the VM going to send data to a braille output device? Anyway, good luck with the lawsuits over arbitrarily making life harder for a bunch of members of a protected class.
One of the benefits here is supposed to be a security improvement, so let's talk about WebAuthn. I'm a big fan of WebAuthn, given that it's a multi-factor authentication mechanism that actually does a good job of protecting against phishing, but if my users are running stuff inside a VM, how do I use it? If you work at Google there's a solution, but that does mean limiting yourself to Chrome Remote Desktop (there are extremely good reasons why this isn't generally available). Microsoft have apparently just specced a mechanism for doing this over RDP, but otherwise you're left doing stuff like forwarding USB over IP, and that means that your USB WebAuthn no longer works locally. It also doesn't work for any other type of WebAuthn token, such as a bluetooth device, or an Apple TouchID sensor, or any of the Windows Hello support. If you're planning on moving to WebAuthn and also planning on moving to remote VM desktops, you're going to have a bad time.
That's the stuff that comes to mind immediately. And sure, maybe each of these issues is irrelevant to most of your users. But the actual question you need to ask is what percentage of your users will hit one or more of these, because if that's more than an insignificant percentage you'll still be staffing all the teams that dealt with hardware, handling local OS installs, worrying about lost or stolen devices, and the glorious future of just being able to stop worrying about this is going to be gone and the financial benefits you promised would appear are probably not going to work out in the same way.
A lot of this falls back to the usual story of corporate IT - understand the needs of your users and whether what you're proposing actually meets them. Almost everything I've described here is a corner case, but if your company is larger than about 20 people there's a high probability that at least one person is going to fall into at least one of these corner cases. You're going to need to spend a lot of time understanding your user population to have a real understanding of what the actual costs are here, and I haven't seen anyone do that work before trying to launch this and (inevitably) going back to just giving people actual computers.
There are alternatives! Modern IDEs tend to support SSHing out to remote hosts to perform builds there, so as long as you're ok with source code being visible on laptops you can at least shift the "I need a workstation with a bunch of CPU" problem out to the cloud. The laptops are going to need to be more expensive because they're also going to need to run more software locally, but it wouldn't surprise me if this ends up being cheaper than the full-on cloud desktop experience in most cases.
Overall, the most important thing to take into account here is that your users almost certainly have more use cases than you expect, and this sort of change is going to have direct impact on the workflow of every single one of your users. Make sure you know how much that's going to be, and take that into consideration when suggesting it'll save you money.
 I have a patchset that makes it safe to use hibernation under Linux even in a secure boot world but it relies on preventing userland from using one of the TPM PCRs[1] that would otherwise be available to it. TPM 2 devices support emulating PCRs in NVRAM, which would obviously be beneficial in not taking away a scare resource, but the docs suggest there's no way to tie a key generation to an NVRAM value which makes this more complicated.
I have a patchset that makes it safe to use hibernation under Linux even in a secure boot world but it relies on preventing userland from using one of the TPM PCRs[1] that would otherwise be available to it. TPM 2 devices support emulating PCRs in NVRAM, which would obviously be beneficial in not taking away a scare resource, but the docs suggest there's no way to tie a key generation to an NVRAM value which makes this more complicated.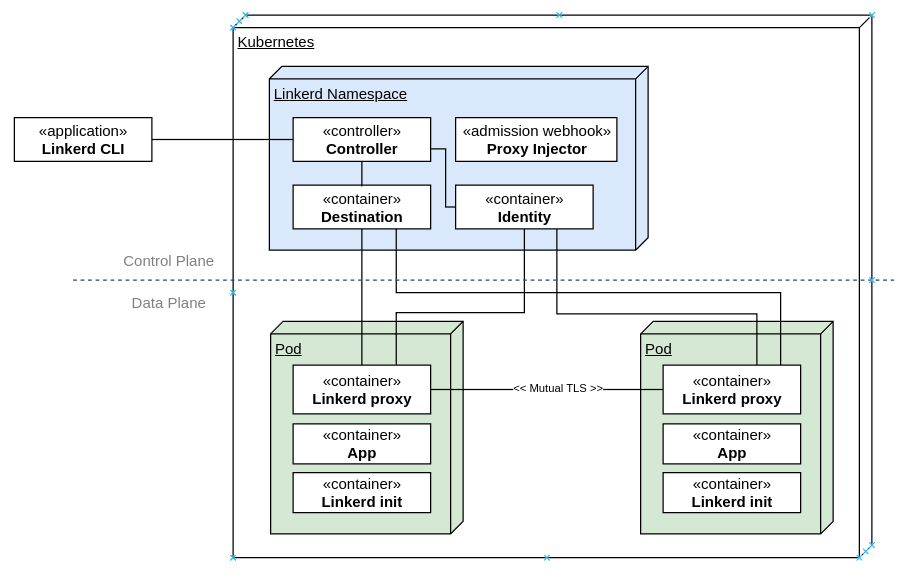
 I m trying to replace my old OpenPGP key with a new one. The old key wasn t compromised or lost or anything
bad. Is still valid, but I plan to get rid of it soon. It was created in 2013.
The new key id fingerprint is:
I m trying to replace my old OpenPGP key with a new one. The old key wasn t compromised or lost or anything
bad. Is still valid, but I plan to get rid of it soon. It was created in 2013.
The new key id fingerprint is:  Our local Debian user group gathered on Sunday October 30th to chat, work on
Debian and do other, non-Debian related hacking :) This time around, we met at
Our local Debian user group gathered on Sunday October 30th to chat, work on
Debian and do other, non-Debian related hacking :) This time around, we met at
 This was our 4th meeting this year and once again, attendance was great: 10
people showed up to work on various things.
Following our bi-monthly schedule, our next meeting should be in December, but
I'm not sure it'll happen. December can be a busy month here and I will have to
poke our mailing list to see if people have the spoons for an event.
This time around, I was able to get a rough log of the Debian work people did:
pollo:
This was our 4th meeting this year and once again, attendance was great: 10
people showed up to work on various things.
Following our bi-monthly schedule, our next meeting should be in December, but
I'm not sure it'll happen. December can be a busy month here and I will have to
poke our mailing list to see if people have the spoons for an event.
This time around, I was able to get a rough log of the Debian work people did:
pollo:



